主题
通往具身通用智能:深度强化学习运动控制 机器人学习
本文介绍具身机器人的深度强化学习(Deep Reinforcement Learning,RL)运动控制方案,包括算法、仿真平台、训练框架、硬件和工具链等。文章来源于萝博派对(RoboParty)
近年来,深度强化学习在足式机器人领域的应用发展迅速。结合模仿学习与大规模人类数据,该领域已涌现出新的技术范式。这种范式为人形机器人底层运动控制器(Controller)的通用化提供了可能。在大语言模型(LLM)的推动下,人形机器人技术取得了显著突破。本文将依次介绍主流的框架和算法,旨在阐述核心原理与必要知识。更多技术细节将通过参考文献进行说明。
深度强化学习理论基础(RL)
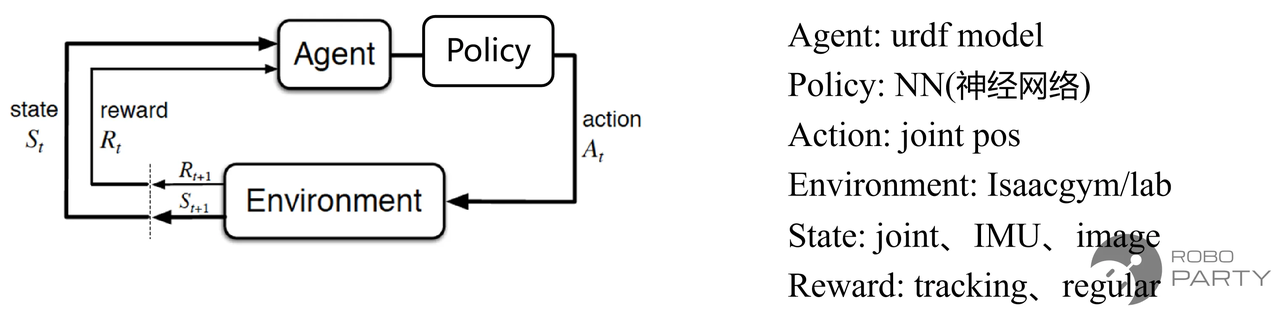
深度强化学习理论框架
深度强化学习(Deep Reinforcement Learning,RL)与强化学习的主要区别在于,前者采用神经网络来实现策略。理解强化学习原理至关重要,本文将从最优控制思想的角度介绍RL算法,进而引出Actor-Critic控制框架及当前广泛应用的PPO算法。关于强化学习更详细的推导和介绍,可参考相关书籍或强化学习的几个主要方法(策略梯度、PPO、REINFORCE实现等)。
如前文所述,强化学习也是一种最优控制方法,其本质基于动态规划原理,属于马尔科夫决策过程,类似于传统优化控制中的DDP。
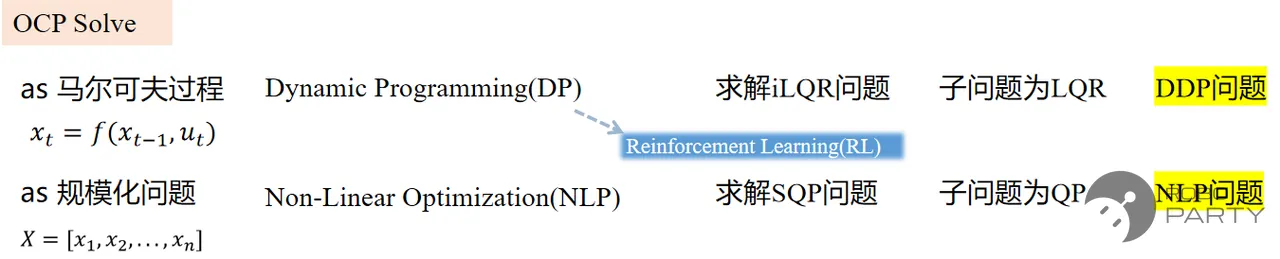
强化学习是一种最优控制方法,基于动态规划,马尔科夫决策过程,和传统运控方法的DDP类似
在利用DDP求解传统运动控制问题时,通常定义两个函数:状态值函数和动作值函数。在强化学习中,同样定义相应的Value function和Q function,二者的来源一致。即Value function和Q function的核心假设均为动态规划与马尔科夫决策过程,其核心原理均为贝尔曼最优。
假设:马尔可夫决策过程(下一时刻状态仅依赖于上一时刻状态和当前输入),即满足动态规划,而动态规划基于代价最优原理。
贝尔曼最优性:从任意时刻 t 开始,剩余问题仍为一个最优控制问题。例如:寻找从北京(起点)到广州(终点)的最短路线(最优策略)。假设最优路线为:北京→石家庄→郑州→武汉→广州。根据贝尔曼最优性原理,该路线中任意一段子路径(如郑州→武汉→广州),必然是“从郑州到广州”的最短路线。若郑州到广州存在更短的路线(如郑州→长沙→广州),则原路线非最优,这与假设矛盾。
Value function:从状态x出发,后续过程均为最优。
Q function: 从状态x出发,针对任意动作u可能面临的所有情况。因此,Value function等价于找到最优决策u对应的Q function。

传统运控的DDP和RL的核心定义相同
最优化问题通过迭代寻找最优解,需要梯度提供方向,因此关键在于获取梯度:DDP必须依赖模型方程,这是求解控制律u时梯度的来源。只有通过模型方程才能计算这些函数的梯度,从而确定目标函数 minJ 迭代收敛的方向。
RL能够实现无模型方程求解,原因在于其利用“概率论+采样”获取梯度。RL在每次决策后会获得一个奖励,该奖励为折现奖励(当前时刻的奖励效用高于未来时刻的奖励,类似于时间折现)。关键在于理解RL梯度的来源,一旦获得梯度,即可进行迭代。

从最优控制OCP问题出发推导RL的梯度来源
经推导,可得到如图红框中的公式,即所需的梯度。具体步骤如下:
通过神经网络得到动作输出(由于Actor网络建模的是动作分布,因此Actor输出均值loc和方差scale,随后利用这两个参数采样得到一个Action作为动作输出),并计算对数概率密度值:
def log_prob(self, value): var = self.scale**2 log_scale = torch.log(self.scale) return -((value - self.loc)**2) / (2 * var) - log_scale - math.log(math.sqrt(2 * math.pi))
收集当前轮次下的累计折现奖励Gt
累加求和并取平均
然而,在实际过程中,Gt具有较大的随机性和方差,因其包含未来所有随机动作及环境噪声,这会导致梯度更新极不稳定。为了在保证梯度无偏的同时降低方差,引入Actor-Critic框架。在已有Actor的基础上,理论上已可进行梯度更新,但方差较大。因此,引入一个新的Critic网络来估计Gt。这使得策略梯度不再单纯依赖于Gt,而是依赖于 $G_t - G_t_critic$。该方法能够去除状态相关的平均回报,仅保留动作选择带来的增量变化,从而避免不同状态带来的不同水平回报的影响。
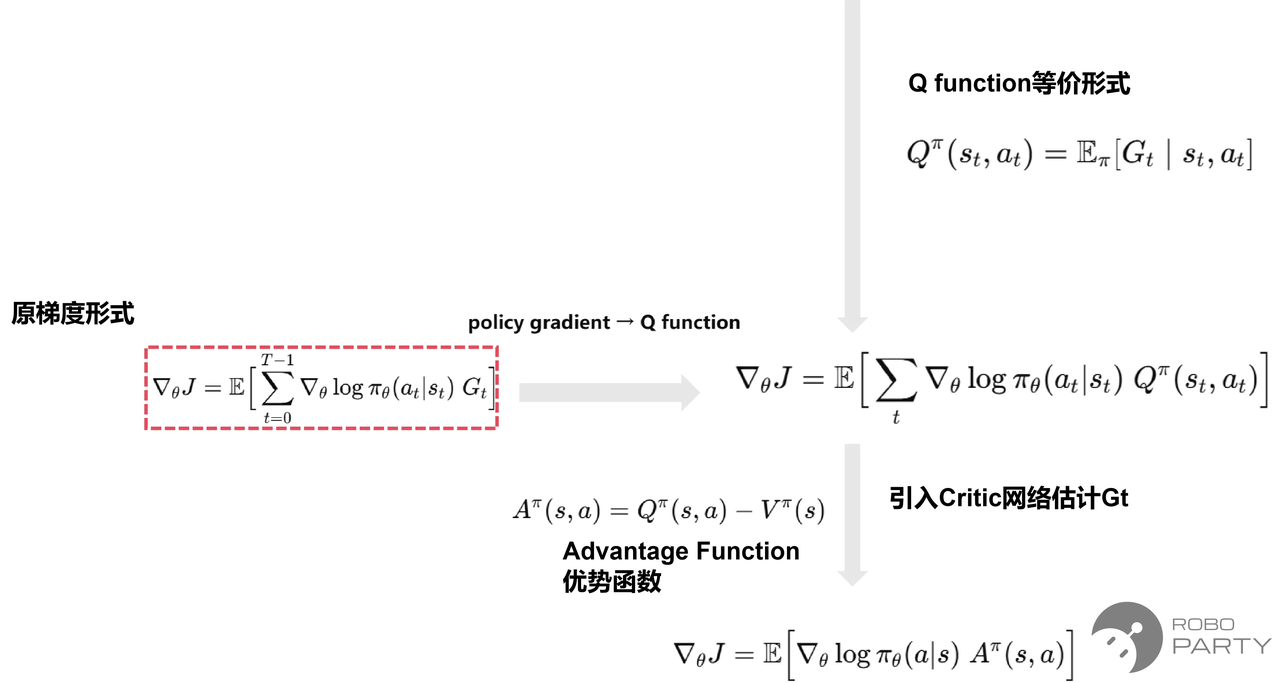
加入Critic估计Gt,由于是batch估计,得到的是一个Gt的平均值,该方法能降低方差
Actor-Critic框架的伪代码如下所示:
c++
初始化 Actor 网络参数 θ
初始化 Critic 网络参数 φ
初始化环境 Env
for episode in 1 to M do
初始化状态 s
for t in 1 to T do
# Actor 根据当前状态选择动作
πθ(a|s) ← Actor 网络输出动作分布
a_t ~ πθ(a|s) # 从策略采样动作
# 执行动作,得到奖励和下一状态
s_{t+1}, r_t ← Env.step(a_t)
# Critic 计算当前状态价值估计
V_φ(s_t) ← Critic 网络预测当前状态价值
V_φ(s_{t+1}) ← Critic 网络预测下一状态价值
# 计算 TD误差(优势估计,δ_t 就是Advantage function)
δ_t = r_t + γ * V_φ(s_{t+1}) - V_φ(s_t)
# Critic 更新:最小化TD误差平方
φ ← φ - η_c * ∇_φ [δ_t²]
# Actor 更新:策略梯度
θ ← θ + η_a * ∇_θ log πθ(a_t | s_t) * δ_t
s ← s_{t+1}
if s is terminal:
breakPPO算法(Proximal Policy Optimization,近端策略优化):尽管在Actor-Critic框架下可获得稳定的梯度,但在实际工程中,仍难以保证梯度更新的幅度。研究表明,若一次策略参数更新幅度过大,可能导致策略分布发生剧烈变化,进而引起训练不稳定甚至性能崩溃,并存在安全隐患。为了使梯度更新更加鲁棒,研究者提出了多种算法,其中PPO是目前强化学习领域应用最为广泛的算法。
一种类比是:如果说Actor-Critic对应于传统优化控制中的内点法或活动集法,那么PPO则对应于线搜索法。前者决定优化梯度的方向,后者决定梯度更新的步长。
PPO算法限制梯度步长的更新通常有两种方式:一种是直接限幅裁剪新旧策略动作的幅度(clip 方法);另一种是通过比较新旧策略分布的KL散度差异来限制步长更新幅度。本文采用使用最为便捷的clip方法实现,其他方法可参考相关文献。
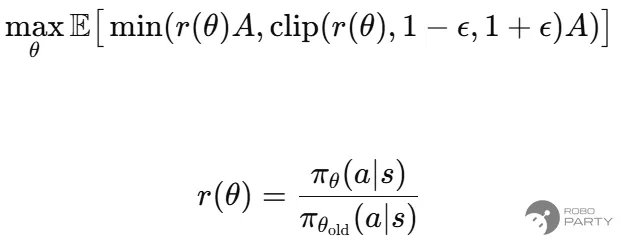
Actor-Critic框架配合PPO的伪代码如下:
c++
初始化策略网络参数 θ_old(Actor)
初始化价值网络参数 φ(Critic)
设置剪切参数 ε,学习率 η_a, η_c
for iteration = 1 to M do
收集一批轨迹数据 {s_t, a_t, r_t, s_{t+1}},用旧策略 π_{θ_old} 采样
计算优势估计 Â_t(比如用 GAE 或 TD误差):
Â_t = r_t + γ * V_φ(s_{t+1}) - V_φ(s_t)
for epoch = 1 to K do
# Actor前向,得到当前策略动作概率
π_θ(a_t|s_t)
# 计算概率比率 r_t(θ),这里是 PPO 关键:
r_t(θ) = π_θ(a_t|s_t) / π_{θ_old}(a_t|s_t) # <-- PPO核心:重要性采样比
# PPO剪切目标:
L_clip = mean( min( r_t(θ) * Â_t,
clip(r_t(θ), 1 - ε, 1 + ε) * Â_t ) ) # <-- PPO核心:限制更新幅度
# Critic价值函数损失(均方误差)
L_vf = mean( (V_φ(s_t) - target_t)^2 )
# target_t = r_t + γ * V_φ(s_{t+1}) 或 GAE返回值
# 熵奖励(鼓励探索,可选)
L_entropy = mean(Entropy(π_θ(·|s_t)))
# 总损失(要最大化策略目标,所以 Actor 损失取负)
Loss = -L_clip + c1 * L_vf - c2 * L_entropy
# 更新策略参数和价值网络参数
θ ← θ - η_a * ∇_θ Loss
φ ← φ - η_c * ∇_φ Loss
end for
# 用当前策略参数更新旧策略参数
θ_old ← θ
end for在后续介绍的人形机器人运动控制深度强化学习方法中,主要涉及深度部分的设计与处理,即神经网络环节的设计。除下节的DAgger算法、Retarget重映射和BFM中的FB算法外,其余方法均通过Actor-Critic框架结合PPO算法实现。因此,在后续的伪代码展示中,将不再详细赘述Actor-Critic框架和PPO算法的具体内容,而是重点阐述深度神经网络框架中的函数。
换言之,上述内容与传统运控的最优控制原理类似,属于共同的基础理论。对于后续内容,本文将重点介绍不同的深度神经网络框架,部分框架可实现鲁棒行走,部分可实现视觉端到端控制,部分可实现舞蹈或全身运动跟踪。尽管本文不列出实战代码,但将尽量提供可供参考的文章和开源代码。
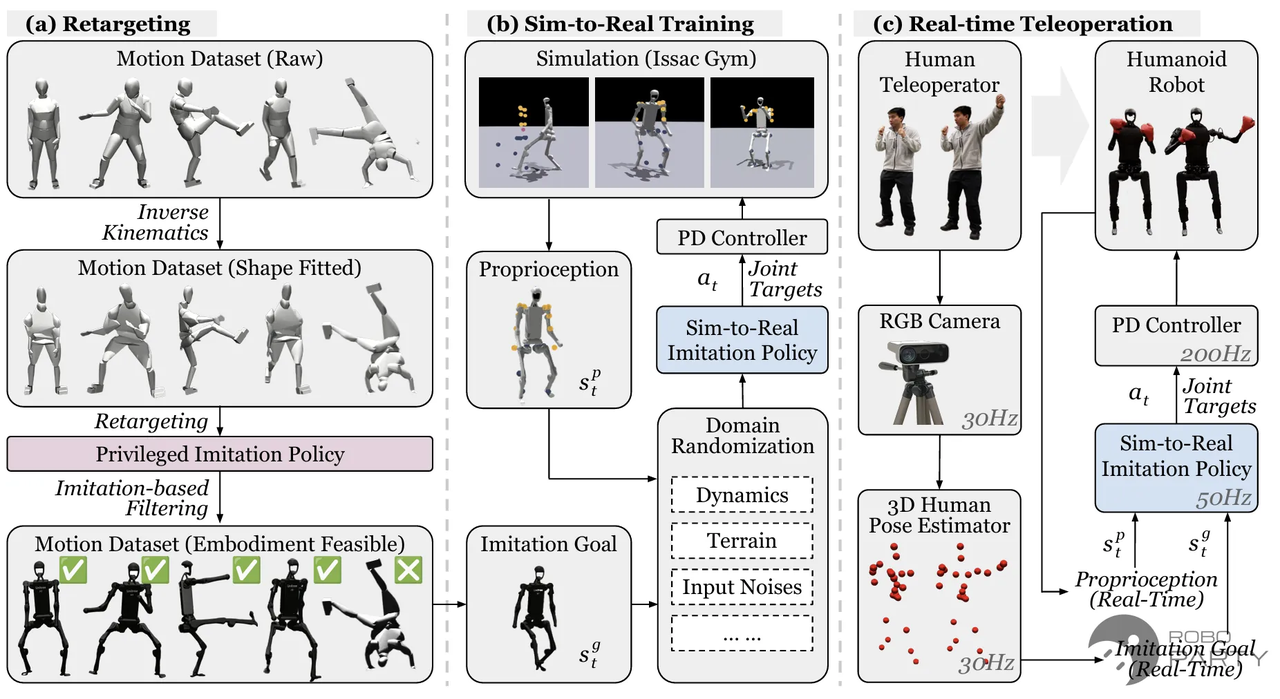
Teacher-Student模型和DAgger训练算法
方法原理
Teacher-Student框架在腿足机器人领域的应用初衷在于提升Sim2Real(仿真到现实)的迁移效果。在Sim2Real技术尚未成熟时,为了实现复杂鲁棒地形的迁移,通常要求机器人在包含噪声、延迟及部分状态不可知的环境中训练,以尽可能模拟实物部署场景。然而,直接训练的效果往往不佳,且适应性较差。为此,ETH提出了一套Teacher-Student训练框架,旨在辅助四足机器人强化学习的落地部署,解决实物部署难题。在当前的rsl_rl库中,仍保留了该框架。
本文此前指出,人形机器人与仿真模型的主要区别在于:仿真环境中的所有数据和状态均为已知且准确。Teacher-Student框架正是利用了这一特性。首先,在一个所有状态均可知(例如质心速度、全局复杂地形,甚至将噪声和干扰力大小作为实时变化的已知状态项)且准确的环境中训练一个策略。虽然该策略无法直接用于实物部署(因为无法实时获取噪声等具体数值),但其代表了在当前机器人结构下所能达到的最优性能,该策略被称为Teacher策略。随后,训练一个可实物部署的策略,使其在存在不可知噪声且状态部分可知的条件下,通过监督学习模仿Teacher策略的输出。这种方法既能获得Teacher策略的性能表现,又能满足实物部署需求。这一监督学习过程被称为蒸馏(distillation),蒸馏得到的可部署策略称为Student策略。Teacher-Student策略通常具有以下作用:
Teacher策略属于特权学习,通常训练出的是完成特定任务的最佳表现。
Student策略无需考虑奖励偏好问题,因其仅针对Teacher策略的Action进行纯监督学习。
Student策略可蒸馏为任意指令形式。例如,Teacher阶段需要全身轨迹参考作为输入,而Student阶段可仅使用质心轨迹参考作为输入,因为Student策略仅计算Action Loss。
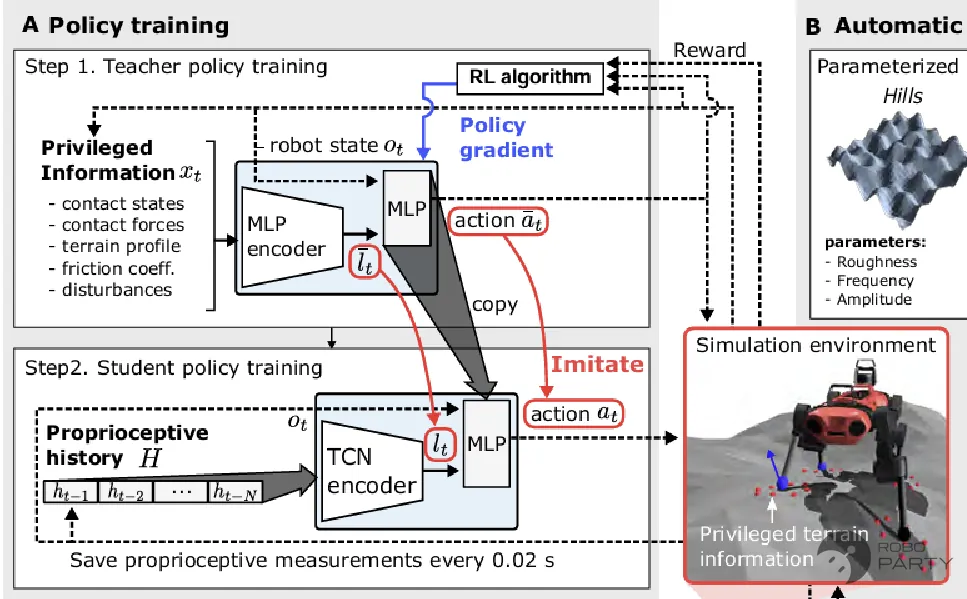
ETH Teacher-Student框架:Student无法获取的信息称为特权信息(Privilege information)
Lee J, Hwangbo J, Wellhausen L, et al. Learning quadrupedal locomotion over challenging terrain[J]. Science robotics, 2020, 5(47): eabc5986.
DAgger算法用于指导Student策略学习Teacher策略。一种直观的方法是利用训练好的Teacher策略在仿真环境中收集大量数据,构建包含**(S_teacher, Action_teacher)状态动作对的数据集。已知S_student是S_teacher的子集,即去除了实物部署时不可知的部分(如具体噪声值、干扰力大小、地形信息(针对盲走场景)、质心速度等),仅保留实物部署时易于获取的状态(如关节角度、关节速度、身体姿态等)。随后,使Student网络输出的Action_student监督学习Action_teacher**,即计算二者之间的MSE误差:

。在此直观方法中,仅在训练Teacher时建立仿真环境以收集数据,训练Student时则不再使用环境交互。然而,该方法存在问题:纯模仿学习通常假设训练数据分布与测试时的环境状态分布一致,但Student策略在实际执行时会进入训练未见过的状态,导致错误累积和性能下降。因此,为解决纯模仿学习中的分布偏移(covariate shift)问题,通常采用DAgger算法,即在线蒸馏。
在线蒸馏的步骤如下:在Student策略学习过程中,需为其单独创建一个交互环境。Teacher策略的输入应为Student在该新环境中交互并更新后得到的状态,而非仅使用Teacher原环境交互过的数据。换言之,Teacher策略需根据Student的状态实时生成新的Action_teacher,随后Action_student 实时监督学习Action_teacher。综上所述,为解决腿足机器人在无视觉条件下跨越复杂地形的问题,首先训练Teacher策略。在Teacher视角下,神经网络可获取所有仿真状态(包括当前噪声大小、干扰大小及地形情况)。由于所有状态已知,Teacher策略在仿真中能够较容易实现复杂地形运动。通过蒸馏至Student网络后,即可在真实机器人上部署具备复杂地形跨越能力的算法。
基本代码
以下给出DAgger算法的伪代码,假设Teacher策略已经训练完成:
python
# Student 策略基于 Action Loss 的更新流程(伪代码)
teacher_policy = mlp(obs_teacher_dim, action_dim) # Teacher网络,由简单三层MLP构成[512, 256, 128]
student_policy = mlp(obs_student_dim, action_dim) # Student网络,由简单三层MLP构成[512, 256, 128]
loss = 0
for epoch in range(num_epochs):
# 让Student与环境交互
obs_teacher, obs_student = env.step(action_student)
# 教师策略前向推理
action_teacher = teacher_policy(obs_teacher).detach() # 已训练好的Teacher策略,detach()表示不进行梯度更新
# 学生策略前向推理
action_student = student_policy(obs_student)
# Action Loss(行为克隆损失)
loss += l2_norm(action_student - action_teacher)
step += 1
# 每 K 步执行一次梯度更新
if step % K == 0:
loss.backward() # 反向传播
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
loss = 0方法局限性
Teacher-Student方法解决了单一网络在存在不可知状态和噪声影响下,难以通过单阶段训练获得良好复杂地形通过能力的问题。其局限性在于:一是训练成本较高,因为需要进行两次训练;二是由于第二阶段为蒸馏过程,Student策略的性能理论上无法超越Teacher策略,且由于直接在Action上计算MSE Loss,Student策略可能会因压缩而导致表现退化。
随着硬件水平的提升,为缩短训练成本并充分利用强化学习的探索优势,后续研究越来越多地探索一阶段复杂地形训练算法。然而,Teacher-Student DAgger框架并未因此被淘汰。随着人形机器人模仿学习的发展,为同时学习更多动作,该框架再次受到关注。
DreamWaq盲走一阶段鲁棒行走训练算法
方法原理
早期采用一阶段学习复杂地形行走未能成功的主要原因,一方面是实物硬件性能受限,仿真与实物之间存在较大差距。例如,ETH长期使用的ANYmal四足机器人关节结构采用SEA(Series Elastic Actuator 串联弹性驱动器),具有较高弹性,这是特定技术阶段的产物。研究团队甚至针对关节建立了专门的分析模型,该关节特性导致的差距在传统控制领域和强化学习阶段均带来了诸多挑战。随着QDD(Quasi-Direct Drive,准直驱)关节力矩电机直驱方案的成熟,早期的一阶段训练方案或许也能获得理想结果。随着QDD方案的成熟,硬件层面带来的问题逐渐得到解决。
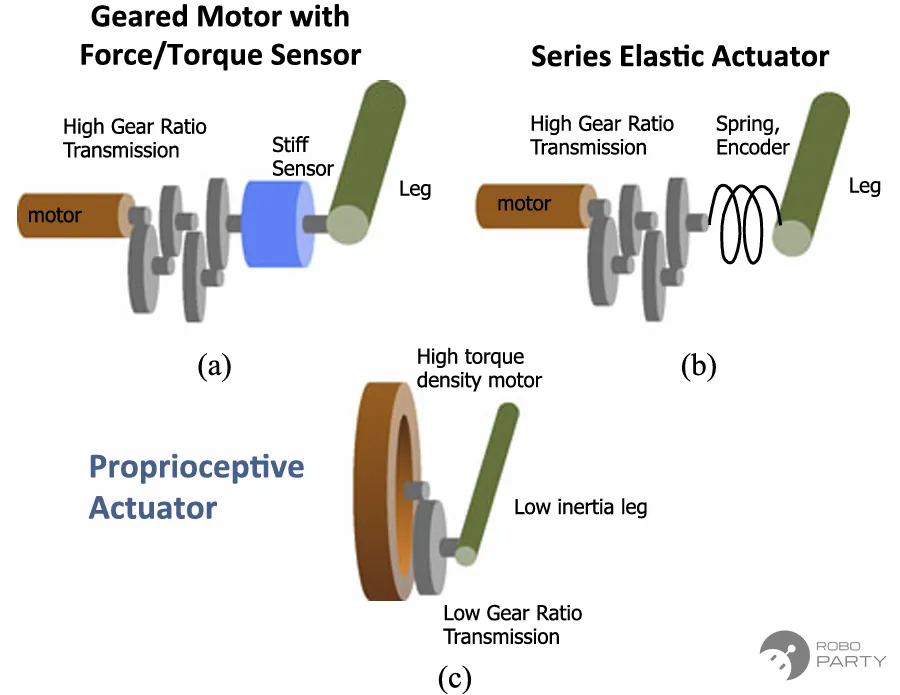
QDD方案出自2017年的MIT Cheetah 2论文:Wensing P M, Wang A, Seok S, et al. Proprioceptive actuator design in the mit cheetah: Impact mitigation and high-bandwidth physical interaction for dynamic legged robots[J]. Ieee transactions on robotics, 2017, 33(3): 509-522.
文章中也对比了SEA的方案
另一方面的原因在于,一阶段训练需直接面对部分状态不可知及存在大量噪声的复杂地形训练问题。复杂地形下的质心速度和质心高度均难以被准确估计。2023年1月,一篇提出DreamWaq算法的论文解决了该问题。其核心思想在于:既然传统方法能够通过卡尔曼滤波实现状态估计,说明质心速度存在内在模型,只是无法被直接准确观测。因此,可以利用神经网络进行状态估计以替代传统方案,从而实现状态可知。该研究在四足机器人上实现了质心速度、质心高度等变量的状态估计,显著提升了机器人一阶段的性能表现。2023年底,本课题组也在人形机器人上实现了基于DreamWaq的鲁棒行走。
DreamWaq方法原论文: Nahrendra I, Yu B, Myung H. DreamWaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning[J]. arXiv preprint arXiv:2301.10602, 2023. DreamWaq人形方法论文: Wang Z, Wei W, Yu R, et al. Toward understanding key estimation in learning robust humanoid locomotion[C]//2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024: 11232-11239.
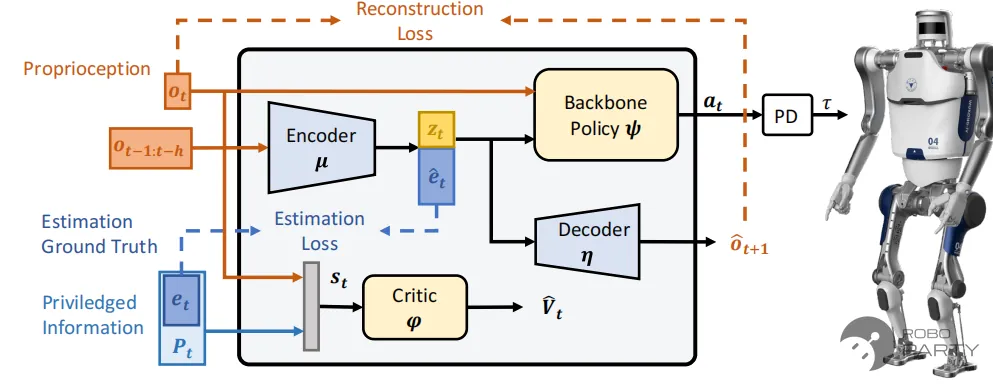
DreamWaq方法在人形机器人的实现,其中Backbone Policy就是Actor网络, Encoder用于压缩编码历史状态和估计不可观的状态,Decoder用于预测下一帧的状态,目的是约束压缩编码具有动力学意义。
以上述框架为例,整体一阶段框架仍采用Actor-Critic+PPO架构。DreamWaq算法主要体现在Estimation loss中,其真值由仿真环境提供,估计值由Encoder网络输出(即et)。估计变量包括质心速度、质心高度及足底周围的地形高度图。根据论文结果及多次实验结果分析,Encoder输出的相关变量对机器人性能提升的重要程度排序如下:
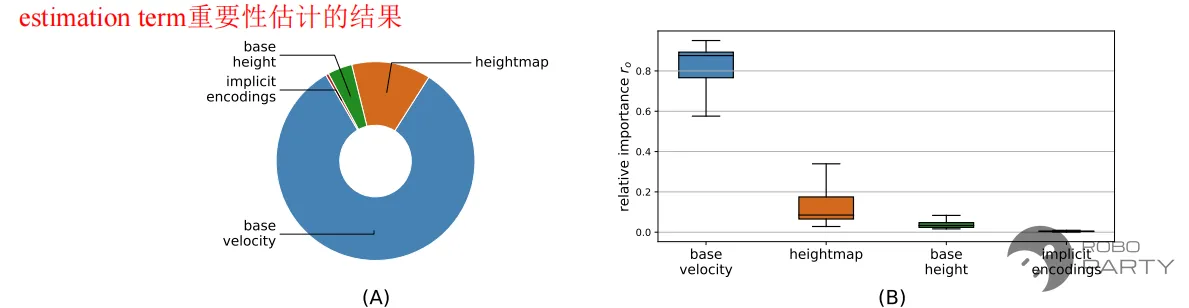
Encoder得到的相关变量重要程度排序,估计速度是非常有效果的
基于DreamWaq得出的结论是:对于鲁棒行走任务,质心速度的估计对提升任务性能最为关键,甚至可以忽略其他变量。该结论的直觉依据在于,对于鲁棒行走任务,质心速度跟踪通常是最重要的奖励项,因此若能准确观测质心速度,性能提升将十分显著。(后续在模仿学习跟踪动作的测试中,应用DreamWaq的提升效果并不明显,即未能带来质的飞跃)。因此,若要在人形或四足机器人上实现带视觉/不带视觉的鲁棒行走,建议尝试该方案,成功实现后可获得类似效果。
基本代码
以下为DreamWaq算法的伪代码,核心包含三个损失函数,网络框架均采用MLP,结构相对简洁。
python
# ===============================
# DreamWaQ: Training Loop
# ===============================
est_dim = com_V_dim + com_h_dim + height_map_dim
encoder = mlp(obs_history_dim, z_dim + est_dim) # mlp均为[512,256,128]
decoder = mlp(z_dim, obs_dim)
policy = mlp(obs_dim + z_dim + est_dim, action_dim)
critic = mlp(priviledge_obs_dim, 1)
for iteration in range(num_iterations):
# ---------- 数据采集 ----------
obs_t = env.get_proprioception() # o_t
obs_hist = env.get_history() # o_{t-1:t-h}
privileged_info = env.get_privileged() # p_t(仅训练可见)
estimation_gt = env.get_estimation_gt() # e_t(训练监督信号)
# ---------- 状态估计(Encoder) ----------
z_t, e_hat_t = encoder(obs_hist) # μ: 编码历史观测
# z_t: latent
# e_hat_t: 估计量
# ---------- 策略执行 ----------
action_t = policy(obs_t, z_t) # ψ: Backbone policy
torque = PD_controller(action_t) # PD 控制
env.step(torque)
# ---------- 动力学重构(Decoder) ----------
obs_hat_t1 = decoder(z_t) # η: 预测下一时刻观测
# ---------- Critic ----------
state_t = concat(obs_t, privileged_info) # s_t(含特权信息)
V_t = critic(state_t) # φ: 价值函数
# ---------- 损失函数 ----------
# 1) 状态估计损失
L_est = mse(e_hat_t, estimation_gt)
# 2) 重构损失
L_rec = mse(obs_hat_t1, obs_t1)
# 3) 强化学习损失(Actor-Critic)
L_actor = policy_loss(action_t, advantage)
L_critic = value_loss(V_t, return_t)
# ---------- 总损失 ----------
L_total = L_actor + L_critic + λ1 * L_est + λ2 * L_rec
# ---------- 参数更新 ----------
optimizer.zero_grad()
L_total.backward()
optimizer.step()方法局限性
该方法的优势在于能够在单阶段训练内实现机器人的鲁棒行走。但实验表明,由于鲁棒行走任务对质心速度跟踪的需求最为强烈,因此质心速度的估计至关重要;若非鲁棒行走任务,该方法的效果则相对有限。
因此,该方法适用于四足机器狗、四轮足机器狗及人形机器人的鲁棒行走任务。若任务涉及多模态控制或模仿学习,且需要在不同重要程度的变量间进行切换,该方法的适用性可能会降低。
PIE感知一阶段鲁棒行走算法
方法原理
DreamWaq算法框架显著提升了四足/人形机器人在无视觉条件下的鲁棒行走能力。为了进一步提升腿式运动的能力,研究人员尝试引入视觉感知。理论上,视觉感知能够实现稳定上下楼梯、爬高台、跳跃沟壑等盲走无法完成的任务。
在DreamWaq框架上集成视觉感知总体上并不复杂,最直接的方法是在状态空间中引入视觉信息。本文以课题组于2023年底在四足机器狗上的研究成果为例,阐述该框架并探讨相关细节。以下内容细节源自论文作者@lsx的解答。
PIE框架 = 视觉 + DreamWaq框架
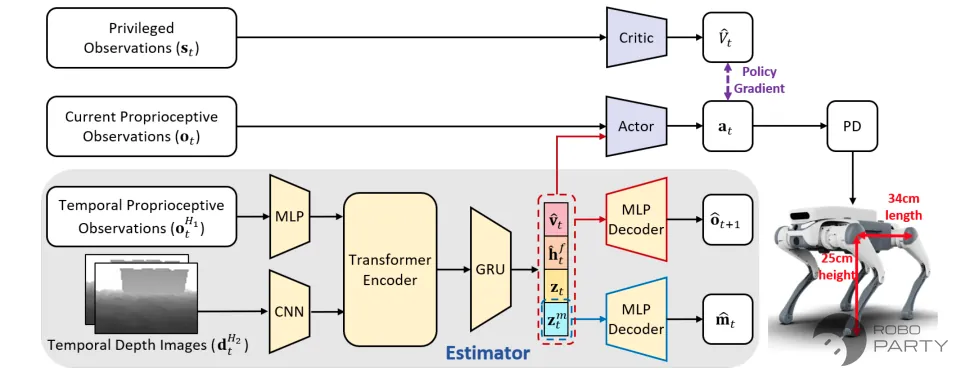
PIE框架总体在DreamWaq基础上增加了视觉信息,出自论文:Luo S, Li S, Yu R, et al. Pie: Parkour with implicit-explicit learning framework for legged robots[J]. IEEE Robotics and Automation Letters, 2024.
对于视觉图像的处理
渲染加速:Isaac Gym自带的渲染接口显存占用过高,渲染速度较慢。采用Nvidia Warp库的光线追踪机制,利用warp kernel在多个机器人和像素点之间进行并行渲染,性能提升数倍。
图片处理:为了追求极致的处理速度,未进行滤波或抗锯齿等操作。图像质量相对于实物RealSense相机而言并非特别高,但这可能反而有利于克服Sim2Real差距。图像未添加噪声,仅增加了时延和位姿随机化。对于距离视线0.1m至2m之间的大块物体而言,开启RealSense的各种spatial、temporal和hole-filling滤波器后,其与仿真图像质量差别不大。
对于Encoder的改进
网络架构:参考LocoTransformer的结构设计编码器。是否使用Transformer并非关键因素,但其可以加速收敛。由于使用的是Transformer Encoder,因此不具备时序记忆功能。最初尝试通过堆叠多帧图像和历史本体信息来保存时序记忆,但学习到的步态始终为Trot步态,且在跳远跳高时也采用Trot步态,表现异常且成功率不高。在后续加入GRU后,步态变得非常自然。
估计值选择:除了DreamWaQ的估计外,由于引入了深度图,因此需要具备对地形的明确感知。在未采用Warp进行渲染时,显存占用过大,并发环境数量仅能达到256或512量级。当仅使用VAE进行地形编码时,模型无法有效学习;使用AE进行地形编码时,地形重构效果较好,但输入给策略的隐向量过于抽象,机器狗在对沟壑等地形进行多次探索失败后,停止运动。只有引入显式地形估计(Ztm),例如显式估计高程图中的全部地形点,才能使机器狗学会跳沟等动作。考虑到真实环境与仿真环境仍存在较大差距,显式估计现实复杂地形时会出现大量分布外场景,因此采用折中方案:显式估计四个抬脚高度,并隐式编码高程图。(若采用光线追踪相机并发大量环境,并设计更合理、细粒度的课程学习,网络结构可以更简单、直接,也能实现有效学习)
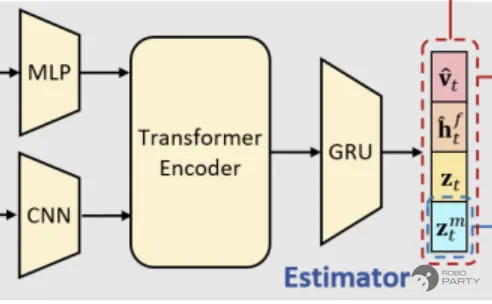
- PIE的Encoder部分
基本代码
python
# --------------------------------
# Network Definitions
# --------------------------------
# Estimator (Temporal Encoder)
proprio_encoder = MLP(obs_hist_dim, enc_dim) # [512, 256, 128]
depth_encoder = CNN(depth_img_shape, enc_dim)
temporal_encoder = TransformerEncoder(enc_dim)
temporal_fusion = GRU(enc_dim, hidden_dim)
# Estimator outputs
latent_head = Linear(hidden_dim, z_dim)
velocity_head = Linear(hidden_dim, v_dim) # \hat{v}_t
height_head = Linear(hidden_dim, h_dim) # \hat{h}_t
# Decoders (auxiliary supervision)
proprio_decoder = MLP(z_dim + v_dim + h_dim, obs_dim) # \hat{o}_{t+1}
height_decoder = MLP(z_dim, height_map_dim) # \hat{m}_t
# Policy & Critic
actor = MLP(obs_dim + z_dim + v_dim + h_dim, action_dim)
critic = MLP(privileged_obs_dim, 1)
# Optimizer
optimizer = Adam(
params = (
proprio_encoder +
depth_encoder +
temporal_encoder +
temporal_fusion +
latent_head +
velocity_head +
height_head +
proprio_decoder +
height_decoder +
actor +
critic
),
lr = lr
)
# --------------------------------
# Training Loop
# --------------------------------
for iteration in range(num_iterations):
# ===============================
# 1. Data Collection
# ===============================
o_t = env.get_proprioception() # current proprioceptive obs
o_hist = env.get_proprio_history() # temporal proprioception
d_hist = env.get_depth_history() # temporal depth images
p_t = env.get_privileged_obs() # privileged state (critic only)
o_tp1 = env.get_next_proprio_gt() # GT next observation
h_gt = env.get_height_map_gt() # GT height map
v_gt = env.get_velocity_gt() # GT base velocity
# ===============================
# 2. State Estimation (Estimator)
# ===============================
# Encode temporal observations
e_prop = proprio_encoder(o_hist)
e_dep = depth_encoder(d_hist)
e_t = e_prop + e_dep # feature fusion
# Temporal modeling
h_enc = temporal_encoder(e_t)
h_t = temporal_fusion(h_enc)
# Estimator outputs
z_t = latent_head(h_t) # latent dynamics code
v_hat_t = velocity_head(h_t) # estimated velocity
h_hat_t = height_head(h_t) # estimated height
# ===============================
# 3. Policy Execution
# ===============================
actor_input = concat(o_t, z_t, v_hat_t, h_hat_t)
a_t = actor(actor_input)
torque = PD_controller(a_t)
env.step(torque)
# ===============================
# 4. Auxiliary Decoding
# ===============================
o_hat_tp1 = proprio_decoder(concat(z_t, v_hat_t, h_hat_t))
h_hat_map = height_decoder(z_t)
# ===============================
# 5. Critic Evaluation
# ===============================
V_t = critic(p_t)
# Advantage & Return (standard GAE / TD)
A_t, R_t = compute_advantage_and_return(V_t)
# ===============================
# 6. Loss Functions
# ===============================
# (1) Estimation loss
L_vel = mse(v_hat_t, v_gt)
L_hgt = mse(h_hat_t, h_gt)
L_est = L_vel + L_hgt
# (2) Reconstruction loss
L_rec_obs = mse(o_hat_tp1, o_tp1)
L_rec_map = mse(h_hat_map, h_gt)
L_rec = L_rec_obs + L_rec_map
# (3) Actor-Critic loss
L_actor = -mean(log_prob(a_t) * A_t)
L_critic = mse(V_t, R_t)
# ===============================
# 7. Total Loss
# ===============================
L_total = (
L_actor +
L_critic +
λ_est * L_est +
λ_rec * L_rec
)
# ===============================
# 8. Optimization Step
# ===============================
optimizer.zero_grad()
L_total.backward()
optimizer.step()方法局限性
视线遮挡:当障碍物距离RealSense过近或RealSense被遮挡时,会产生较大噪声。由于缺乏针对此类问题的处理机制,系统在高草丛等视线遮挡环境下表现不佳。(计划在后续工作中改进)
仅能前向运动:训练地形仅包含前向运动和转弯,由于仅有前向视角,难以利用视觉信息实现全向移动,操作不便。(计划在后续工作中改进)。
遇墙大跳:训练中的高台地形均为机器狗能够跳上的高度。对于机器狗搭载的RealSense相机的视场角(FOV)而言,0.75m的高台已无法看到顶部,因此被识别为墙壁。因此,当机器人看到墙壁时也会将其误判为高台,在手柄控制距离较近时会尝试跳跃。
训练地形单一:野外环境主要依赖系统的鲁棒性,未进行专门训练。对于镂空工业楼梯等特殊场景,属于完全分布外场景,需要引入更加丰富的地形环境进行训练。
Attention落足点优化算法
方法原理
前文实现了盲走与感知的鲁棒行走。然而,前述纯强化学习方法相较于传统基于模型的方法,在稀疏地形上缺乏精度。Attention-Based Map Encoding for Learning Generalized Legged Locomotion提出了一种结合强化学习与注意力机制的方法,旨在解决足式机器人在复杂及稀疏地形上的运动问题。
该方法主要基于多头注意力模块。该模块不仅接收地形高度图,还以机器人本体感知状态(如速度指令、当前姿态)为条件。该机制使得网络能够依据机器人运动意图,动态关注地形图中对当前决策起关键作用的区域(例如即将踩踏的落脚点),而非无差别处理整个地图。
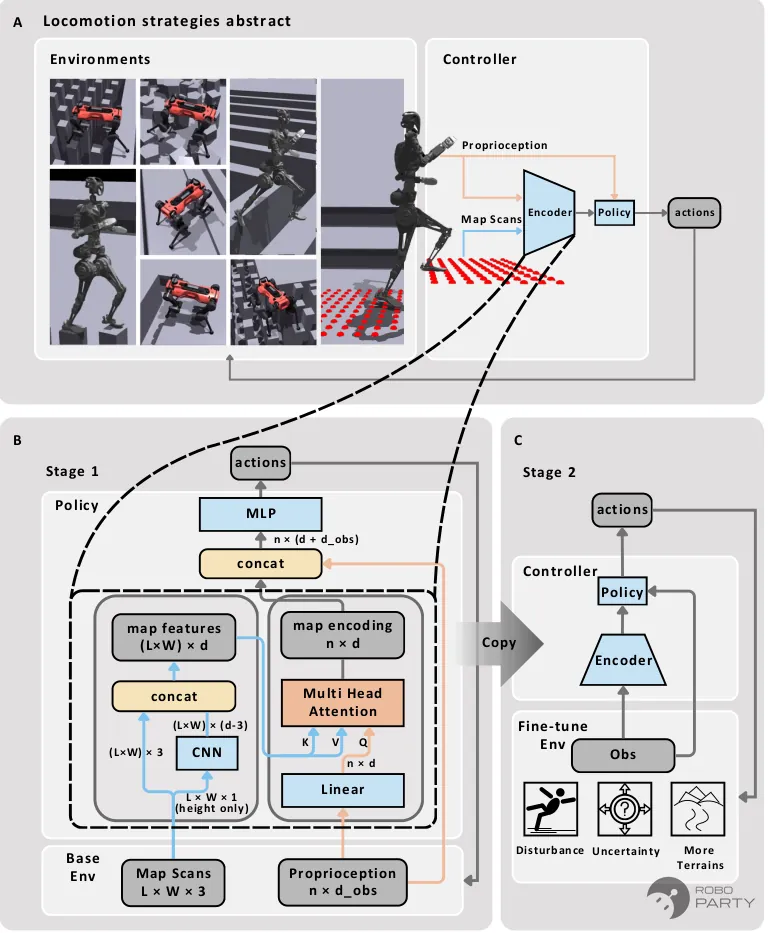
ETH Attention落足点方法示意图。参考论文:Attention-Based Map Encoding for Learning Generalized Legged Locomotion
与许多黑盒神经网络不同,该方法的注意力权重具备可解释性。研究表明,高注意力区域通常对应于最佳的未来落脚点。这表明网络习得了一种隐式的“落脚点选择”机制,为解析神经网络的地形感知机制提供了直观依据。
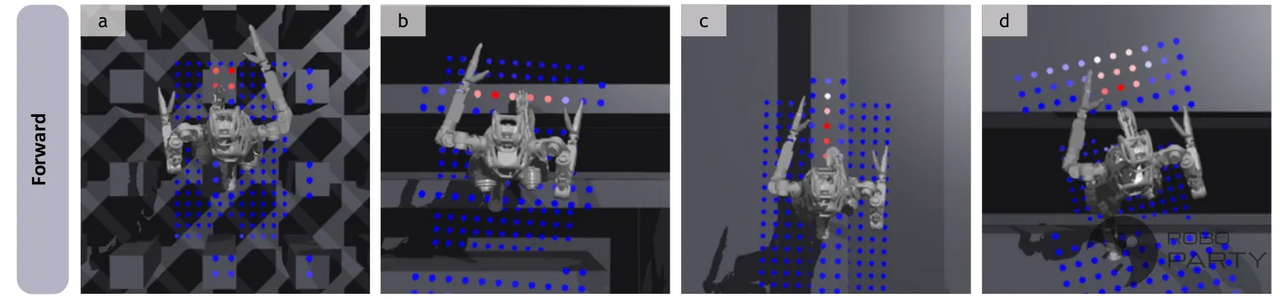
算法实现的核心细节如下:
逐点特征提取的MHA:系统首先利用轻量级卷积神经网络对以机器人为中心的局部高程图进行扫描,提取每个网格点周围的坡度、边缘等局部几何特征。随后,显式地将每个点相对于机器人的三维空间坐标$$(x, y, z)$$拼接到特征向量中,生成兼具“几何语义”与“空间位置”信息的独立特征序列。这些特征最终作为注意力机制中的键和值,使网络能够依据机器人运动意图精确索引并关注特定地形落脚点,从而在保留高精度的同时实现对复杂稀疏地形的有效编码。
两阶段训练流程:为获取兼具鲁棒性与泛化能力的地图编码,设计了分阶段训练流程,旨在逐步优化控制器性能。第一阶段在具备完美感知的基础地形上进行训练。该阶段对地图编码学习进行预热,使控制器能够利用真值传感数据习得基本运动技能。第二阶段引入包含扰动和不确定性的复杂地形。这些地形模拟了感知存在缺陷的真实环境,从而提升运动策略的适应性与韧性。通过将机器人置于多样化地形环境并施加额外扰动,该阶段不仅提升了控制器的泛化能力,还增强了其对现实世界不确定性的鲁棒性,确保习得的地图编码在未见环境中有效运行。
基本代码
python
# --------------------------------
# Network Definitions
# --------------------------------
# Embedding
proprio_encoder = MLP(obs_dim, embedding_dim)
feature_extractor = CNN(1, embedding_dim - 3)
# MHA
mha = nn.MultiheadAttention(embedding_dim, num_heads)
# Policy & Critic
actor = MLP(obs_dim + embedding_dim, action_dim)
critic = MLP(privileged_obs_dim + embedding_dim, 1)
# Layer norm
ln_q = LayerNorm(embedding_dim)
ln_kv = LayerNorm(embedding_dim)
ln_out = LayerNorm(embedding_dim)
# Optimizer
optimizer = Adam(
params = (
proprio_encoder +
feature_extractor +
mha +
actor +
critic
),
lr = lr
)
# --------------------------------
# Training Loop
# --------------------------------
for iteration in range(num_iterations):
# ===============================
# 1. Data Collection
# ===============================
o_t = env.get_proprioception() # proprioceptive obs
m_t = env.get_map() # map
s_t = env.get_states() # state (critic only)
pos_encoding = create_position_encoding() # pos_encoding
# ===============================
# 2. State Estimation (Estimator)
# ===============================
# Encode and feature extract
embedding = proprio_encoder(o_t)
feature = feature_extractor(m_t)
pointwise_feature = concat(feature, pos_encoding) # Pointwise feature
# Q&KV
q = ln_q(proprio_embedding)
kv = ln_kv(pointwise_features)
# Attention
attn_output = mha(
query=q,
key=kv,
value=kv
)
map_encoding = ln_out(attn_output)
# ===============================
# 3. Policy Execution
# ===============================
actor_input = concat(o_t, map_encoding)
a_t = actor(actor_input)
torque = PD_controller(a_t)
env.step(torque)
# ===============================
# 4. Critic Evaluation
# ===============================
V_t = critic(s_t)
# Advantage & Return (standard GAE / TD)
A_t, R_t = compute_advantage_and_return(V_t)
# ===============================
# 5. Loss Functions
# ===============================
L_actor = -mean(log_prob(a_t) * A_t)
L_critic = mse(V_t, R_t)
# ===============================
# 6. Total Loss
# ===============================
L_total = (
L_actor +
L_critic +
)
# ===============================
# 7. Optimization Step
# ===============================
optimizer.zero_grad()
L_total.backward()
optimizer.step()方法局限性
端到端训练过程及注意力模块的引入导致训练耗时较长,通常需要数天时间。注意力模块略微增加了推理计算负载,需在机载计算机算力与实时性之间进行权衡。
该方法本质上仍依赖视觉或激光雷达生成的局部地图。若环境感知严重退化(如浓烟、强光干扰导致地图错误)或出现严重分布外(OOD)情况,其性能可能低于盲走策略。
该方法依赖于从高程图采样生成的机器人中心高度图。该表示方式属于2.5D表示,虽对大多数地面有效,但无法有效表示复杂3D几何结构(如悬垂物、洞穴顶部或复杂立体空间),限制了其在某些极端环境下的应用。
模仿学习基础:人-机器人重映射算法
方法原理
后续将介绍基于数据集学习的模仿学习与强化学习算法,即利用用于监督学习的机器人仿人动作数据集进行学习。得益于虚拟角色设计和计算机图形学几十年来对人体动作数据的需求,产出了如AMASS、LAFAN1、OMOMO等开源人体数据集。这些数据集均由专业的动捕演员身穿动捕服采集得到。
随着人工智能的发展及数据集需求的增长,动捕采集效率较低的局限性逐渐显现,因此提出了从视频中采集数据的需求。鉴于互联网视频资源丰富,后续开源数据集的规模得以大幅扩展,例如Motion-X、Motion-X++、Humanoid-X等。这些数据集不仅包含人体数据,通常还包含对应动作的文本标签。
上述提及但未提供链接的数据集地址:https://github.com/myismyname/awesome-bfm-papers
开源数据集中的人体数据通常采用标准格式,统称为SMPL。这是一种参数化人体模型,包括pose(θ)和shape(beta)参数。其中pose描述人体关节点位姿,shape描述人体体型差异。

SMPL经典格式的24个关节+shape参数含义
SMPL格式通常包含SMPL、SMPL-H、SMPL-X
SMPL: 能够用**形状参数 β(≈10 维)与姿态参数 θ(24*3维)**生成完整的三维网格
SMPL-H: 在 SMPL 的基础上加入了双手的关节和细节, 每只手 14 个手指关节, 即姿态参数 θ(52*3维)
SMPL-X: 在 SMPL 基础上加入全身手部(MANO)与表情面部(FLAME),形成统一的55 个关节模型,能够一次性捕获身体‑手‑脸的细节,即姿态参数 θ(55*3维)
更多SMPL内容请参考:https://zhuanlan.zhihu.com/p/696878001
重映射过程是指将SMPL格式的人体数据(来源包括动捕或视频估算)拟合至机器人各关节的对应位置。机器人的关节数量未必与人体pose数量一致,需选取合适的对应关系。

重映射过程
从人体SMPL格式数据到机器人的具体重映射步骤(通常无论采用何种SMPL格式,前24*3维的关节序号如上图所示,一般情况下,模仿学习采用该24个关节即可)
获取数据集参数,包括数据集中的shape、pose、root(全局位姿)三个参数。
坐标轴统一,由于SMPL全局坐标系可能为Y-up或Z-up,建议统一转换至Z-up坐标系。选取并root对齐,以人体pelvis为身体坐标系原点进行对齐(pelvis原本可能不为0)。
确定SMPL关节与机器人关节的对应关系,不追求1:1对应,仅需功能匹配。若机器人关节数量多于SMPL关节数量,需施加约束或正则化。
必须先拟合shape(beta)参数,即将数据集人体SMPL数据缩放至对应机器人的shape。目前主要有两种方式:
优化法(PHC论文方法):选定一个或多个合适位姿(如站立平举),将人体24*3维参数及机器人关节均设置为该位姿(URDF可视化)。将shape参数设为优化变量,理论上收敛时人体与机器人选定对应关节的位姿应相同(至少位置相同),此时优化得到的shape参数即为所求。
放缩法(GMR论文方法):全局放缩与局部放缩结合。全局放缩即按照身高/腿长比例缩放全局XYZ;局部缩放即按照对应各连杆长度人为给定缩放因子进行缩放(该人为设计虽不完全符合运动学约束,但由于shape参数对最终拟合结果敏感性较低,仍可采用)。
拟合关键点位姿,以下结合现有的三种方法进行比较分析。 第一种为PHC论文的方法,单纯在关键点位之间进行梯度下降拟合。其优点在于无硬约束限制,可采用ADAM等GPU并行优化器,实现多动作同时优化;缺点在于缺乏约束,所得结果有时无法保证合理性。
第二种为GMR论文中的方法,采用Mink库进行求解,具有严格的运动学约束(Mink是Pinocchio逆解库pink的衍生)。这也是GMR重映射效果及后续训练效果良好的原因。此外,逆解本身耗时低,使得GMR的重映射可以实时进行。其缺点在于对多接触效果处理不佳,对多约束缺乏严格的硬约束。
第三种为Omiretarget论文中的方法。该方法核心在于随机采样更多关键点,并以拉普拉斯变换能量最小为原则进行拟合,天然适应多接触和无接触的重映射场景,且采用cvxpy求解器可处理多约束。其缺点在于计算耗时较长。
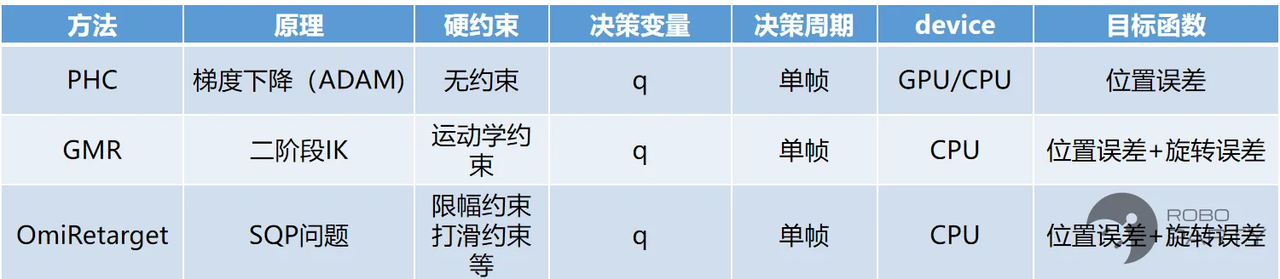
- 现有三种重映射方法的比较
人形机器人领域现有的三篇开源重映射论文及其地址如下:
PHC方法:He T, Luo Z, He X, et al. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning[J]. arXiv preprint arXiv:2406.08858, 2024.
开源地址:https://github.com/LeCAR-Lab/human2humanoid
GMR方法:Araujo J P, Ze Y, Xu P, et al. Retargeting matters: General motion retargeting for humanoid motion tracking[J]. arXiv preprint arXiv:2510.02252, 2025.
开源地址:https://github.com/YanjieZe/GMR
Omiretarget:Yang L, Huang X, Wu Z, et al. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction[J]. arXiv preprint arXiv:2509.26633, 2025.
- 分析与结论 从这三种重映射方法的迭代改进可以看出,方法的改进不仅提升了重映射效果,也优化了后续强化学习训练的效果与效率。由此得出一个共同结论:越符合运动学约束和规律的重映射方案,在后续的强化学习环节越易于学习,无需特别调整奖励函数。
PHC缺乏约束,GMR具备严格运动学约束(通过运动学逆解IK保证),Omiretarget在扩大采样点数以符合运动学约束的基础上,严格求解SQP优化问题。基于此,本文尝试求解一个完整的轨迹规划(TO)问题(若为实时重映射,则求解MPC问题;面对多约束场景可换用更高效的优化求解器,通过C++实现)。实验表明,该方法相比现有方法展现出更好的效果。前提是具备性能良好的人形机器人本体。根据经验,最终效果的影响程度排序为:人形机器人本体 > 重映射轨迹质量 > RL算法。
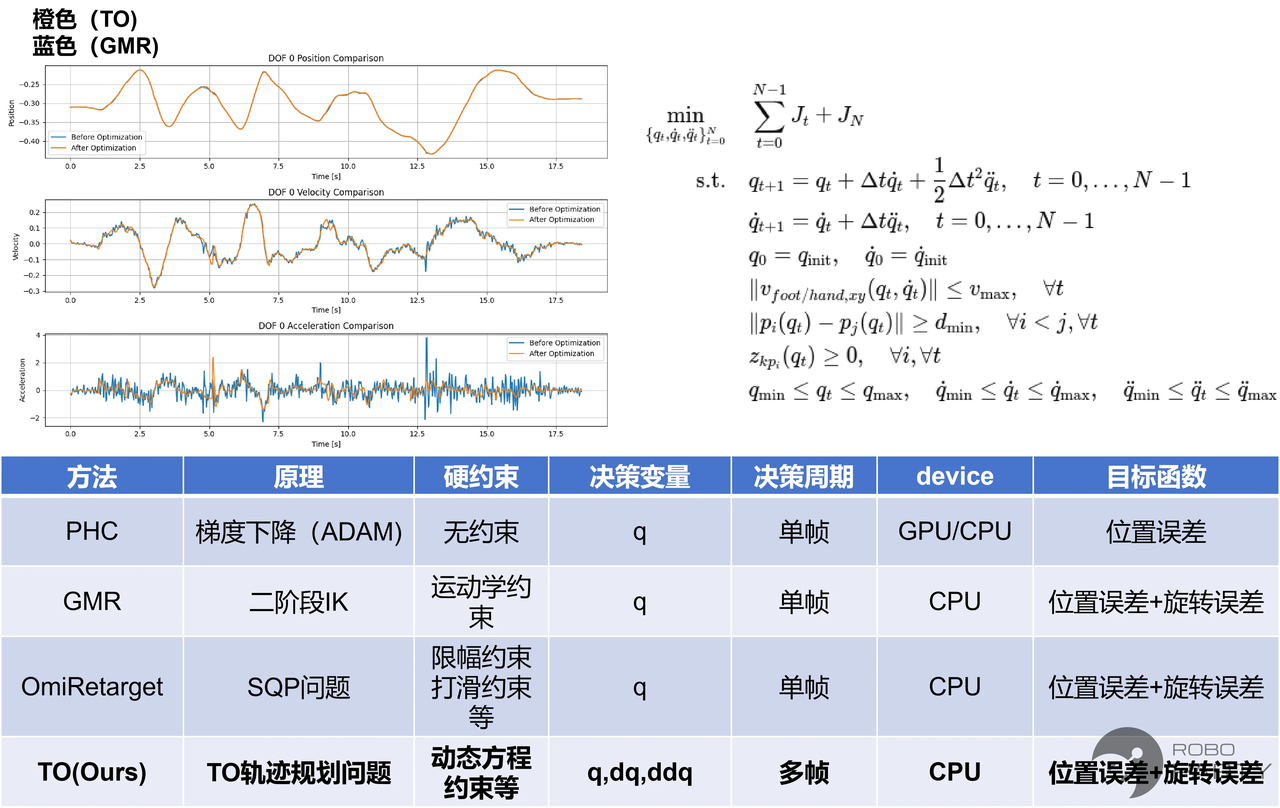
轨迹优化的效果
为何轨迹质量越高,强化学习越无需调整奖励?除本体因素外,这是因为强化学习仿真最终基于隐式动力学。机器人的运动只有在指定位置、速度和加速度后才会产生确定的轨迹,即确定的解。因此,当尝试将关节位置、速度和加速度均加入优化问题,并考虑多帧联合优化时,将所得轨迹用于强化学习训练,在RL探索求解的过程中,那些连续且不突变的解往往易于找到并收敛。而在重映射阶段保证了运动学连续性,使得RL训练过程更为顺利。相反,若参考轨迹经常突变,即使位置连续但速度突变,由于底层动力学仿真具有连续性,也会导致RL难以找到解。
方法局限性
然而,实践表明,重映射算法的效果受限于两个前提:一是具备高性能的人形机器人本体,二是SMPL数据来源于高质量数据源(如AMASS)。由于年代较为久远,AMASS数据集的质量存在局限性,而视频数据的整体质量亦有不足。虽然可以训练出有效的策略,但难以达到“卓越”的评价标准。对比LAFAN和AMASS数据集的训练结果,差异较为明显。随着BFM算法的发展,未来数据集缺口可能进一步扩大。在购买数据与投入时间处理数据之间的权衡将成为一个重要挑战,两者均具有较高的成本。
Deepmimic模仿学习+强化学习算法(跳舞)
方法原理
完成人体动作到机器人的重映射工作后,可获得用于人形机器人训练的数据集。
得益于计算机图形学的发展,Xuebin Peng于2018年提出了DeepMimic方法,该方法最初应用于多关节角色控制,旨在利用现有的大量人体数据集进行模仿学习与强化学习。
与机械臂VLA相比,在人形机器人领域优先应用强化学习是较为自然的路径。机械臂作为固定基座系统,主要受运动学约束(工业机械臂多采用位置控制),对动力学可行性要求相对较低。相比之下,人形机器人若未充分考虑动力学特性,极易失稳跌倒。因此,研究人员通常先采用强化学习实现机器人的稳定行走。
随着基于强化学习的人形行走控制逐渐成熟,将模仿学习与强化学习结合成为必然趋势。强化学习由奖励函数驱动,在实现鲁棒行走后,目标可从单纯的质心速度奖励转向全身关节轨迹跟踪奖励。鉴于存在可用的轨迹数据集,且奖励函数设计为全关节轨迹跟踪,该方法即构成了模仿学习。这使得人形机器人能够天然地结合模仿学习与强化学习。后续的舞蹈动作多基于此方法训练生成(仿人行走更多采用下文所述的AMP方法)。因此,人形机器人模仿学习与强化学习的核心原理在于:将强化学习的奖励函数调整为跟踪期望轨迹的奖励(包括质心和关节)。
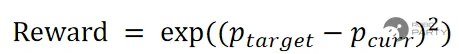
跟踪奖励函数示意图
- Human2Humanoid:CMU的Tairan He首次提出了完整的人形机器人模仿学习架构(此前Exbody仅实现了上半身跟踪)。该架构利用Zhengyi Luo提出的PHC重映射算法,具体结构如下:
Human2Humanoid架构。参考开源地址:https://github.com/LeCAR-Lab/human2humanoid
BeyondMimic:UC Berkeley的Qiayuan Liao于2025年发布的beyondmimic是目前人形机器人领域主流的代码框架。作者在优化控制领域具有深厚造诣,其此前开源的四足机器人控制成果NMPC+WBC已在NMPC相关章节中提及。
模仿学习+强化学习训练的关键点
具备性能良好的本体、合适的PD参数及清晰的代码框架(本体的性能至关重要)
高质量的重映射轨迹
自适应采样算法:为使机器人完整学习舞蹈动作,将动作序列切分为N段时长为1秒的片段。根据失败次数计算概率,并按概率进行环境重置,从而提高高难度动作被选中重置的概率。
Reference State Initialization (RSI):在期望轨迹附近随机重置机器人状态,无需严格按照时间顺序学习轨迹。
Early Termination:在特定条件满足时提前终止当前训练回合,避免机器人在倒地状态下继续尝试模仿动作,从而防止无效学习污染数据。
方法局限性
在DeepMimic方法中,机器人学习的核心目标是跟踪期望轨迹,通常仅能学习数据集中已存在的轨迹。这通常会导致以下问题:
在数据集规模较小的情况下,机器人动作泛化能力较差,仅能掌握数据集中已有的动作。
鲁棒性及新地形适应能力较弱,尤其在机器人硬件性能受限的情况下。
需要完整的期望轨迹作为输入,因此DeepMimic通常应用于舞蹈等场景,难以直接用于仅包含质心指令的手柄控制任务,除非采用多阶段蒸馏训练。
AMP模仿学习与强化学习算法(仿人行走)
方法原理
AMP(Adversarial Motion Priors,对抗运动先验)由Xuebin Peng于2021年在计算机图形学的角色控制领域提出,旨在解决DeepMimic算法依赖完整轨迹作为硬性输入的问题。在人形机器人领域的AMP开源实现中,可参考zitongbai提供的legged_lab库及rsl_rl库中的AMP模块。
AMP的核心原理基于生成对抗网络,通过对抗训练使机器人在执行任务的同时生成符合参考运动风格(如人类动作捕捉数据)的自然动作。其核心特点在于,即使在小规模数据集上也能学习到具有数据集风格特征的动作。尽管训练过程使用了参考轨迹,但由于算法学习的是运动风格而非具体轨迹,因此在部署阶段无需任何参考轨迹,从而能够在单阶段内实现基于手柄等质心任务指令的控制。
- 风格学习与部署阶段轨迹无关性的实现机制
主要原因在于AMP在原有的Actor-Critic网络架构基础上引入了判别器网络(Discriminator)。判别器网络的作用是区分策略生成的动作与数据集中的动作。策略网络(即Actor)的目标是生成与数据集尽可能相似的动作,以欺骗判别器。在训练初期,Actor无法输出正确的动作,易被判别器识别;训练的目标是使Actor最终能够欺骗判别器。与此同时,判别器也在持续训练,旨在尽可能识别出非数据集类的动作。因此,Actor与Discriminator通过对抗过程进行训练,这正是对抗网络的含义。
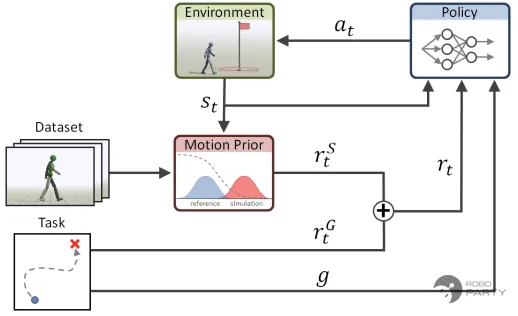
AMP网络框架:Actor-Critic + Discriminator.Peng X B, Ma Z, Abbeel P, et al. Amp: Adversarial motion priors for stylized physics-based character control[J]. ACM Transactions on Graphics (ToG), 2021, 40(4): 1-20.
- 核心机制:判别器网络的独立更新与风格奖励的融合
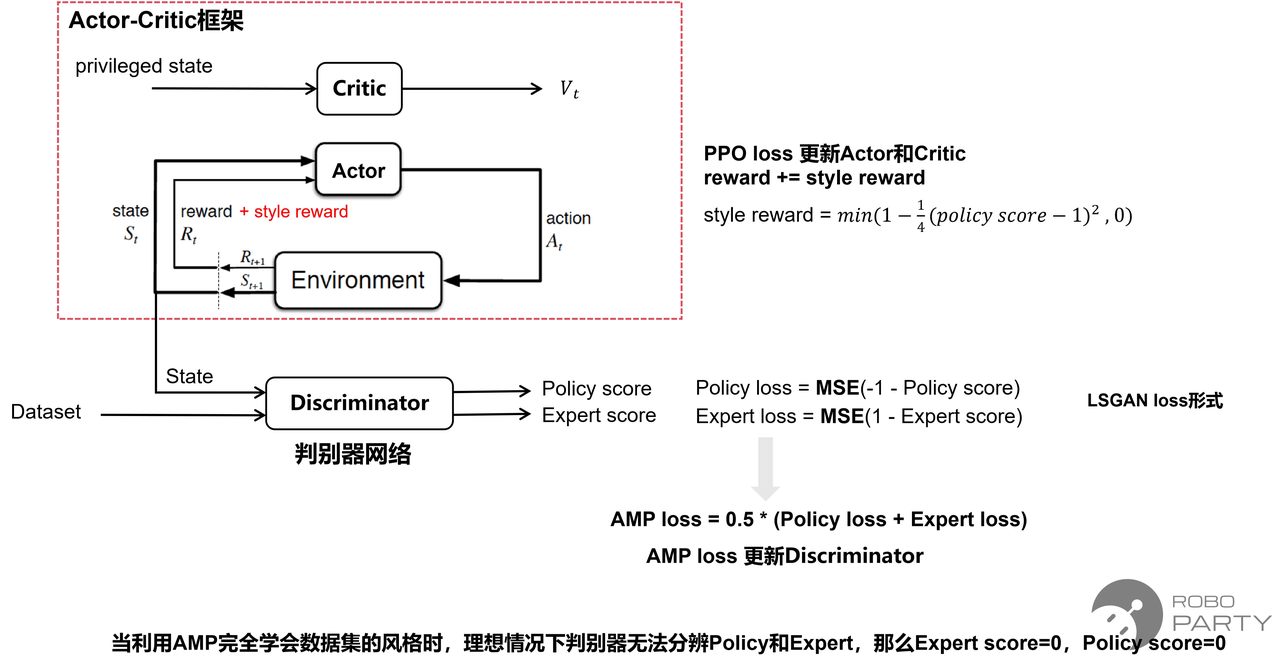
AMP网络框架
实际训练中的Expert score与Policy score分析: 在实际训练过程中,即使人形机器人已成功学习到稳定且自然的AMP行走行为,仍常观察到判别器对专家轨迹与策略轨迹给出显著不同的评分:专家轨迹的Expert score通常接近0.9,而策略轨迹的Policy score则接近−0.9。该现象并不代表策略未能成功模仿专家行为,而是对抗模仿学习框架下的正常结果。
原因在于,AMP判别器的训练目标并非判断“运动是否可行或自然”,而是区分来自专家数据分布与策略生成分布的差异。即使策略在宏观运动形态上已高度接近专家,其生成的轨迹仍不可避免地在状态分布、时序相关性及高频细节等方面与离线专家数据存在系统性偏差。因此,判别器仍能利用这些细微但一致的统计差异对两者进行区分,导致Expert score与Policy score在数值上保持较大间隔。
进一步研究表明,当使用已训练策略生成的期望轨迹作为判别器的“专家参考”,而非原始的重映射动作捕捉轨迹时,Expert score与Policy score分别收敛至约0.2与−0.2。该结果符合预期,因为此时判别器面对的两类轨迹实际上来源于高度相似的策略分布,其可区分性显著降低。
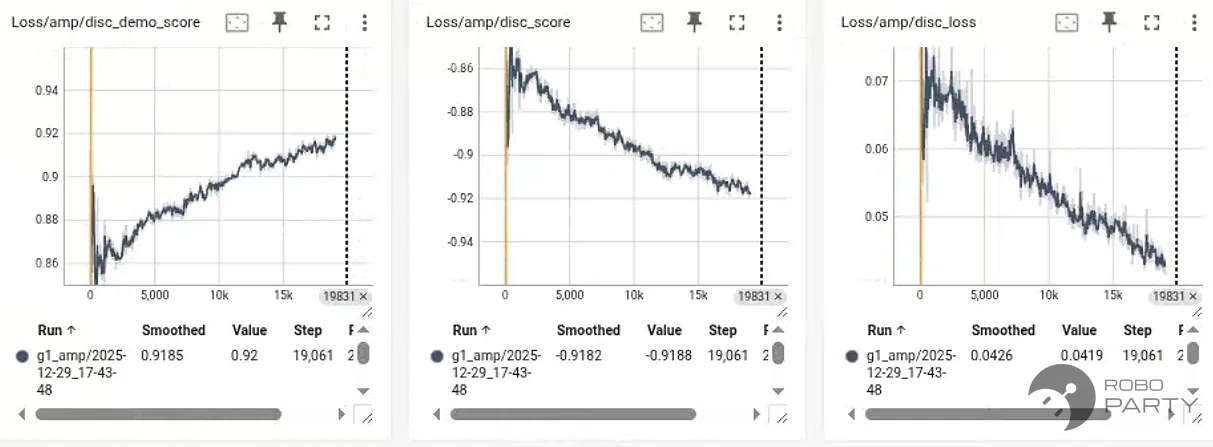
实际训练成功的Expert score和Policy score往往不是0,而是只比+-1小一点
对抗网络下的模式崩溃问题:当数据集中包含多种风格或多种行为时,Actor仅需学会其中一种即可获得较高的风格奖励,从而缺乏探索其他动作的动力。解决模式崩溃的关键点包括:
尽量保证数据集中的风格统一
引入其他奖励项(如仿人行走中的步态奖励),以避免Actor陷入局部最优
在判别器网络中添加权重损失,防止网络过拟合至局部细节
平衡判别器网络的输入帧数。输入帧数过少会导致描述机器人运动的信息不足,时间跨度过短
当风格差异显著时,可在不同环境下采用不同的判别器网络
基本代码
python
# Networks
actor = Policy()
critic = Value()
disc = Discriminator()
for iter in range(num_iterations):
# -------- Rollout --------
s = env.reset()
traj = []
for t in range(T):
a = actor(s)
s_next, r_task = env.step(a)
feat = motion_feature(s, a, s_next)
traj.append((s, a, r_task, feat))
s = s_next
# -------- Discriminator --------
feat_exp = sample_expert_motion()
feat_pol = [x.feat for x in traj]
L_disc = -log(disc(feat_exp)) - log(1 - disc(feat_pol))
disc.update(L_disc)
# -------- Style Reward --------
for x in traj:
r_style = -log(1 - disc(x.feat))
x.r = x.r_task + λ * r_style
# -------- Actor-Critic --------
A, R = compute_advantage(traj, critic)
actor.update( -log_prob(actor, traj) * A )
critic.update( mse(critic(traj.s), R) )方法局限性
由于AMP的原理旨在学习风格,这一特性既是其优势也是其局限。若需进行精确轨迹跟踪的模仿学习,仅使用AMP难以取得理想效果,因为AMP无论如何都存在一定程度的模式崩溃,仅能学习风格特征。此外,与DeepMimic方法相比,AMP对期望轨迹的质量更为敏感。若期望轨迹本身存在打滑或突变等情况,AMP往往难以有效学习。
另外,无论是DeepMimic方法还是AMP方法,均存在对复杂地形和复杂任务适应能力不足的问题。对于上下台阶、斜坡等任务,仍需具备对应的数据集作为参考标准。若数据集中仅包含平地行走数据而缺乏上台阶数据,无论是DeepMimic还是AMP,目前均无法表现出良好的性能。
BFM行为基础模型算法
本章将介绍目前最前沿的算法框架,这些算法框架旨在实现多动作学习(单策略实现多个动作)。其中,TWIST/SONIC框架基于现有大量数据集的优势进行多阶段/单阶段的模仿学习,BFM-Zero则是基于无监督的FB算法框架(替代PPO)实现的模仿学习。
BFM(Behavior Foundation Model, 行为基础模型)这一概念最早源于Meta 2024年的文章Fast Imitation via Behavior Foundation Models。早期的BFM主要指代基于无监督学习算法框架FB(Forward-Backward)的研究。直到2025年的综述A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots中,**将BFM概念扩展为三类范式的集合:FB、Deepmimic、Intrinsic reward。**其中FB和Deepmimic的相关方法后续将主要介绍,Intrinsic reward(内在奖励模型)指代一类好奇心探索奖励,该奖励机制已被集成在Isaac_lab的rsl环境中,被称为rnd,相关内容可进一步探索。
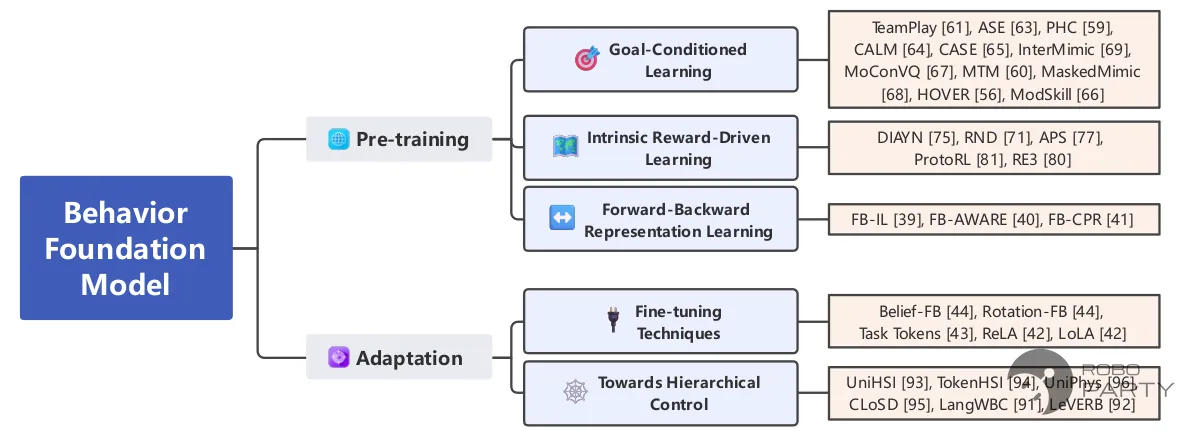
BFM分类
BFM的显著特征在于,其所使用的模型规模、算力消耗与数据量呈现明显上升趋势,这揭示了模仿学习+强化学习的Scaling Law(缩放定律),该定律的成功有望推动人形机器人迈向通用化道路:
上述提到的所有BFM相关文章均在:https://github.com/myismyname/awesome-bfm-papers/tree/main
基于Teacher-Student多动作学习
方法原理
早期研究已涉足人形机器人的模仿学习领域,当时ExBody和Human2Humanoid刚发表新论文,主要涉及单策略的单动作学习。因此,研究方向从那时起便聚焦于单策略的多动作模仿学习。
对于单策略多动作的模仿学习,基于课题组在阶段学习方面的经验,初始目标是开发一种单策略、一阶段训练,且能学会多动作并具有鲁棒性的策略。在初期,训练中成功实现了行走、奔跑、蹲起等动作的同步学习。但在后续加入踢腿、打拳等高动态动作时,发现会导致机器人所有动作的学习效果均出现下降。同时,研究也发现奔跑数据集在一定程度上有利于行走的掌握。
尽管后续尝试了以下方法:
在一阶段训练中加入类似于ASAP的学习课程,以引导收敛;
将最终输出的Action由单纯的PD控制改变为带有期望位置和期望速度的增量PD控制(即残差控制)。
这两种方法确实对机器人的表现有所提升:方法1牺牲了鲁棒性;方法2显著改善了机器人表现(主要依靠位置控制提升),但最终仍未能使机器人完美学会所有动作。得出的结论是:单策略多动作学习通常需要同时训练整个数据集。由于数据集中既包含低动态数据,又包含高动态数据,还包含类似单腿平衡的准静态数据,同时训练会导致梯度方向互相冲突,从而无法有效学习。
受限于算力资源,且当时Locomotion领域的算力普遍停留在单卡4090的水平,基于Teacher-Student方式成为一种理想的选择。其核心思想在于:鉴于同时训练所有数据集存在梯度冲突,可采用分离训练策略。首先在第一阶段利用Teacher训练多个不同的策略,例如训练一个策略负责低动态动作,一个负责高动态动作,一个负责准静态动作;然后在第二阶段利用Student网络将其蒸馏为一个策略。通常,基于Teacher-Student方法的单策略多动作训练分为三个阶段:
- Teacher训练多个策略(多个Teacher)
该阶段的核心在于数据集的分类,通常有两种方法。一种是人工预先分类数据集,可直接人工挑选出行走、奔跑、跳跃、踢腿、拳击、单腿平衡的数据集;若无标签,也可采用K-means等无监督分类方式进行分类。另一种是采用PHC论文的方法,需要训练一个评估函数,初始化第一个teacher网络,每训练一段时间后进行评估,筛选出尚未学会的动作,并初始化第二个teacher网络,同时冻结第一个teacher网络。该方法即不断用新网络去学习难度递增的动作,被称为Hard mining机制。
需要注意的是,Teacher阶段的学习结合了模仿学习与强化学习。
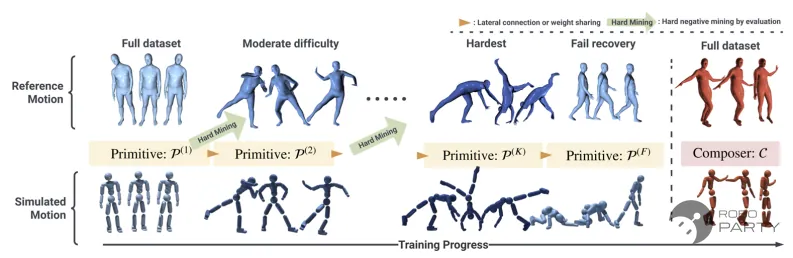
Hard mining机制,参考PHC论文:
Luo Z, Cao J, Kitani K, et al. Perpetual humanoid control for real-time simulated avatars[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 10895-10904.
- Student蒸馏到一个策略
(若在Teacher阶段最后使用加权网络/门控网络先将各个teacher策略合并,此处则直接蒸馏student,无需区分环境。)
在Teacher阶段获得了多个teacher策略,由于不同动作属于不同的teacher策略,在蒸馏时需要区分环境进行训练。例如,训练了三个teacher分别对应行走、奔跑、跳跃,包含的数据集动作数量分别为行走10、奔跑20、跳跃30。那么在蒸馏student时,最好设置 N * (10 + 20 + 30)个环境,例如6000个,其中1000个用于行走,2000个用于奔跑,3000个用于跳跃,与动作数量保持一致。(若不一致也可训练,例如6000个环境平均分配各2000个用于不同teacher策略蒸馏,但实验表明按比例分配效果更佳,且更符合“平均”定义。)
需要注意的是,在蒸馏过程中,Student的训练是一个纯监督学习的过程,即Loss仅为Action loss。
部分Student蒸馏的Loss采用KL散度去拟合Teacher的分布,这也是一种可行路径。这样可以省去第三阶段的微调,但前提是最终策略更倾向于风格迁移,而非轨迹跟踪。
参考TWIST论文:TWIST: Teleoperated Whole-Body Imitation System
- 强化学习微调(RL-finetune)
进行该步骤的核心原因在于,Student阶段的训练仅为单纯的模仿学习,在缺乏强化学习奖励偏好的作用下,机器人在模仿过程中摔倒并不会被判定为“严重禁止的行为”。因此,若直接部署Student策略,机器人摔倒的概率极高,尤其是在人形机器人本体性能不佳的情况下。
因此,有必要进行强化学习微调。微调方式通常是在冻结Student网络结构的基础上,新初始化一个小的Actor_res网络。采用与Student阶段相同的训练环境分配,但在该阶段,仅训练Actor_res网络。此外,在该阶段,Loss除了PPO的Loss外,还可加入一个KL散度的Loss用于正则化最终的Action输出分布,使Actor_res不会过度影响整体动作分布,而仅起到微调作用。
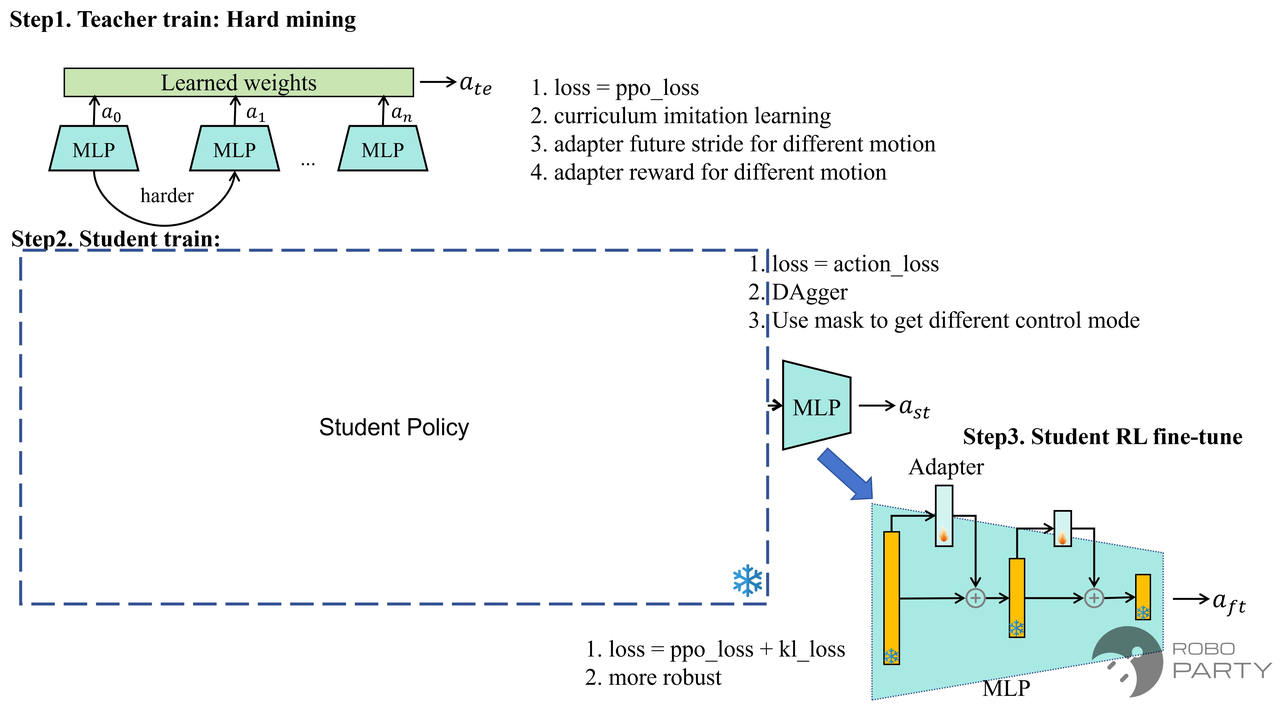
Teacher-Student模仿学习三阶段训练的一种方法
另一种方法可参考Track Any Motions under Any Disturbances,利用World model引导微调。
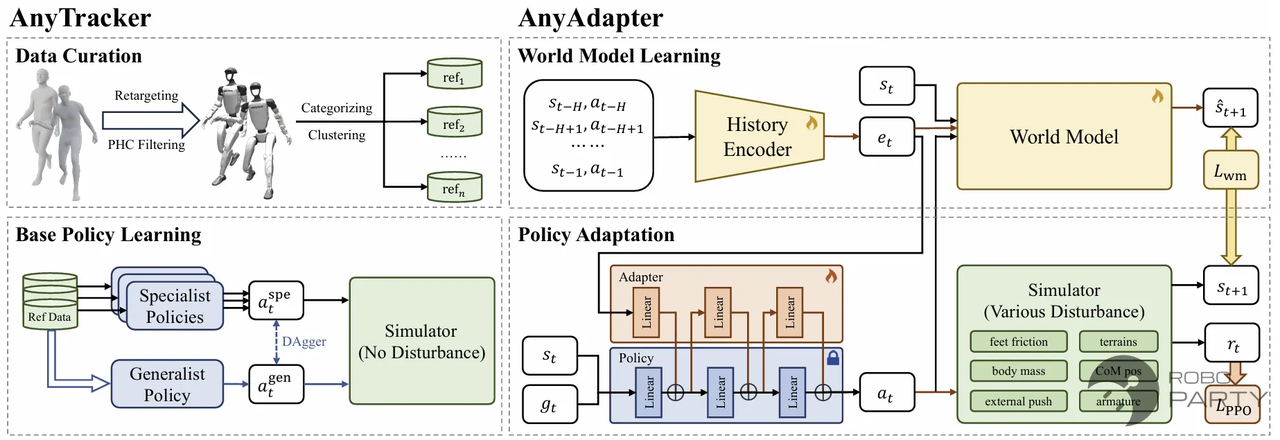
Track Any Motions under Any Disturbances论文方法,同样是一个三阶段框架,且该方法在第三阶段能保证更强的鲁棒性。
基本代码
python
# Teacher阶段训练多个策略
teacher_policy_i = mlp_i(obs_teacher) # mlp结构为[512,256,128]
loss = PPO_loss
# 可选多专家融合
# Student阶段蒸馏到一个策略
env_nums = sum(N * [motion_1_nums, motion_2_nums, motion_3 nums])
# motion_1_nums使用teacher_policy_1,motion_2_nums使用teacher_policy_2,motion_3_nums使用teacher_policy_3,
student_policy = DAgger(obs_student, teacher_policy)
loss = action_loss
# RL-finetune阶段
init actor_res = mlp
freeze(student_policy)
loss = PPO_loss + kl_loss方法局限性
采用Teacher-Student方法进行多动作模仿学习时,受限于计算资源、硬件和视野,虽然最终实现了单策略下的多动作,但局限性依然明显:
训练阶段长,工程量较大;优势在于算力资源需求较低,若细节处理得当,单卡4090即可获得良好效果。
若要实现人形机器人通用化,需要更大量的数据,采用此方法实现通用化的工程量将显著增加。
在Teacher-Student框架下,机器人的跟踪能力和鲁棒性容易被压缩和丢失。
基于Deepmimic(SONIC)
方法原理
2025年末的论文SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control探索了模仿学习+强化学习的Scaling Law,即若提供足够多的数据、足够大的环境数量和足够深的网络,强化学习即可学会几乎任何动作。该论文作者为CMU刚毕业的博士 Zhengyi Luo,其在博士期间的研究内容即为探索基于仿人橡皮人的多动作模仿学习,其多项工作(PHC, PULSE)均对人形机器人的模仿学习和强化学习算法具有指导意义。
SONIC论文框架
SONIC论文框架包含丰富内容,例如将数据集扩大至100M帧(一亿帧数据),使用不同的encoder编码不同模态,采用FSQ区分不同特征的动作,并结合上层的planner网络进行相关部署等。分析认为,SONIC的核心贡献在于验证了模仿学习+强化学习的Scaling Law,这与Zhengyi Luo博士答辩中阐述的未来研究方向一致。
Zhengyi Luo在其博士答辩中的思考。https://www.bilibili.com/video/BV1Nza1zKED2/?spm_id_from=333.337.search-card.all.click&vd_source=30216de2308cf451749cc50ccb881d29
SONIC复现实验与结论
实验设置:
仅使用一个mlp作为Actor网络在Unitree G1机器人上进行测试(无encoder,actor输入完整轨迹),控制频率和数据集轨迹频率均为50Hz。
采用beyondmimic作为底座,并修改为多动作导入训练框架,多动作导入方式参考SONIC将其拼接为一个动作。
分别尝试了0.4M帧的LAFAN,10M帧的LAFAN+AMASS进行训练。
实验结论:
措施重要程度:自适应采样 > 环境数 > 网络参数容量 > 未来帧。
自适应采样方式与SONIC一致。
环境数不足会导致奖励无法收敛,或收敛至非理想结果,验证了SONIC论文中的观点。大数据集下想要学会所有动作需要一定数量的环境数+一定深度的网络。
需要较大的显存容量,0.4M帧需要84096,10M帧需要484096。
未来帧对倒地爬起及机器人稳定性有较大帮助。
训练数据量上升会增加机器人的鲁棒性,但若数据质量不佳,会导致跟踪效果变差。因此,数据质量仍是一个关键指标。
效果与人形机器人本体性能强相关,若机器人本身PD控制不足、力矩不足或运动范围不足,训练效果必然受限。
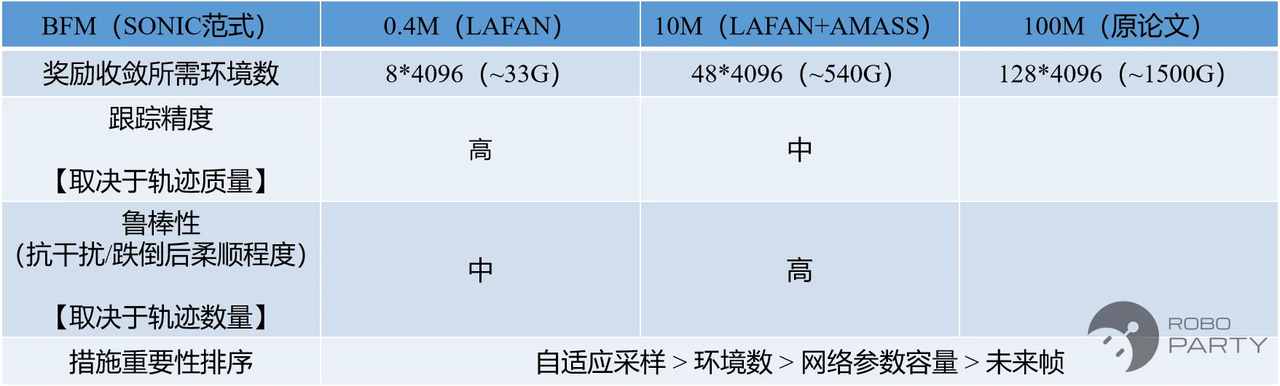
- 测试结论
方法局限性
SONIC最重要的价值在于验证了模仿学习+强化学习的Scaling Law,尤其是环境数不足导致奖励函数无法收敛至预期结果这一结论得到了验证。然而,这种“力大砖飞”的方法也存在一定局限性:
这意味着人形机器人运控已进入大数据和大算力时代,算力缺口巨大,鲜有实验室具备相应条件。实验中LAFAN+AMASS数据集采用6块H20显卡训练了5天。
前期的数据集处理需要耗费大量时间,无论是从SONIC论文还是西湖大学的GAE访谈中均可感受到处理和挑选数据集所消耗的成本。
交互不友好。本质上Deepmimic方法学到的是一个动作字典,一旦动作超出分布(Out of distribution),动作容易变得剧烈,例如跟踪走路时突然倒地,要么在地上抽搐,要么突然弹起,动作幅度很大。这背后的原因在于训练时为了学出良好效果和数据利用率,采用了Early termination(早停机制),导致机器人对某些误差产生“畏惧”,因此在超过容忍误差时,仅追求最快恢复。(接下来的BFM-Zero方法能从理论上解决该问题)。
基于FB的无监督学习(BFM-Zero)
方法原理
基于FB(Forward Backward)原理的无监督强化学习也是实现人形机器人多动作学习并可能迈向通用化的一种途径。其核心思想在于:
在训练阶段,可在无数据集辅助的情况下,假设随机采样的隐空间已包含所有动作特征,即可从隐空间Z中进行充分采样,采取某种方式将特征Z与机器人状态S绑定,并训练Actor。
在推理阶段,只要能将期望达到的状态S_goal编码到对应的隐空间特征Z上,再将其输入Actor,即可使机器人达到状态S_goal。
2025年底的论文BFM-Zero:A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning是参考 Meta motivo 橡皮人BFM项目的人形机器人实现。
- FB训练原理:特征隐空间采样,特征Z和机器人状态S绑定,利用FB(Forward Backward)算法更新参数。
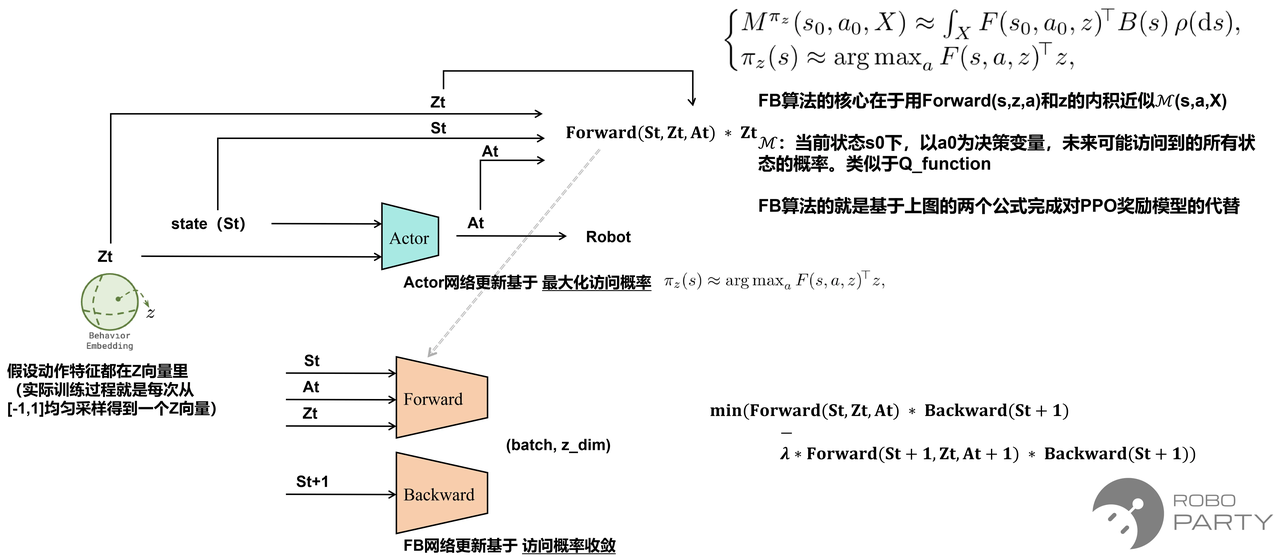
FB算法框架的更新原理,替代了PPO的奖励模型
重要!!:利用FB框架,Actor找到的action是在当前状态s和特征z的约束下,能走到访问概率最大的下一个状态。尽管z在训练过程中是随机采样得到的,但FB框架采用了B(s)后向网络,在Actor收敛的过程中,建立了不同状态s和特征z的关系。
正是由于特征z在初始阶段无任何标签含义,仅将step后得到的下一时刻状态St+1作为目标状态,因此理论上保证了动力学的连续性,使得训练出的策略动作非常柔顺。
实际过程中对于Z的采样通常采用混合采样形式,即均匀采样+从B(s)网络采样,以使动力学更稳定。
FB推理阶段:分为无微调推理和有微调推理。
- 无微调推理:由于训练时已建立不同状态s和特征z的关系,此时的Backward网络B(s)已完全是一个可由目标状态S_goal编码出运动特征z的网络,因此可实现以下三个场景:

有微调推理:实际过程中可能面临Out of distribution的情况,例如未见过的负重,会导致机器人无法正常完成动作,此时需要微调(Adaption)。重点是,此处的微调无需微调网络参数,而是微调S_goal编码出来的特征z。
假设要执行单腿站立,但现在有负重导致机器人out of distribution,先正常通过单腿站立S_goal推出Z_init。
构建损失函数J(z),以最大化单腿站立奖励为目标,优化得到新的Z_adap,将其输入Actor。
FBCPR训练原理:虽然是无监督训练,但在人形机器人上使用该算法框架,训练出的动作虽能实现Goal reaching、Motion tracking、Reward guide,却不一定具备拟人特性(动力学连续,但可不遵循拟人动力学)。
这也是BFM-Zero文章中利用LAFAN数据集配合GANloss的意义,旨在正则化训练动作,使其更加拟人。
FBCPR = FB +GANloss + penalty reward(碰撞,关节超限惩罚)。
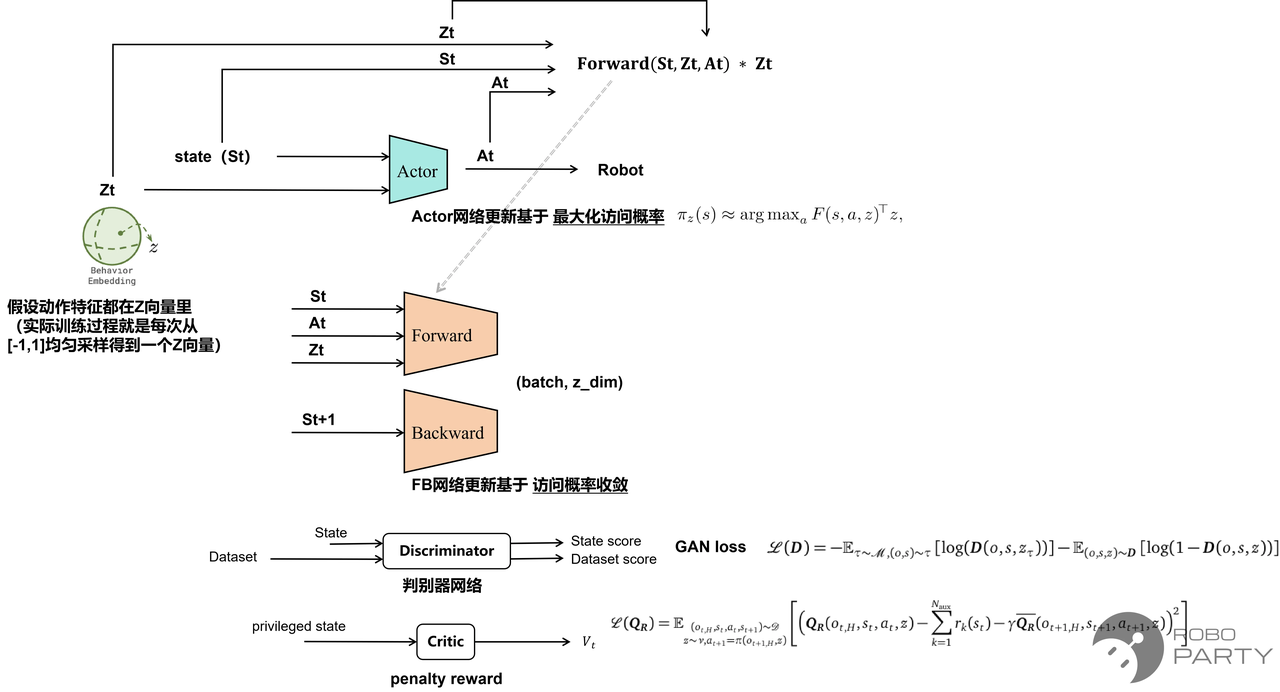
FBCPR:在FB框架基础上加入GAN网络和Critic网络,均用于正则化人形机器人的行为
基本代码
以下为FB框架下的伪代码
python
# ===================== FB (Forward-Backward) 算法 核心更新框架 极简伪代码 =====================
def update(replay_buffer):
# 1. 从经验池采样batch数据
obs, action, next_obs, terminated = replay_buffer.sample_batch()
discount = γ * (1 - terminated) # γ:折扣因子,终止状态无后续收益
# 2. 观测归一化 + 采样隐变量z
obs, next_obs = normalize(obs), normalize(next_obs)
z = sample_z(train_goal=next_obs)
# 3. 核心步骤1:更新 前向映射F + 反向映射B 网络 (FB核心)
fb_metrics = update_FB(obs, action, next_obs, discount, z)
# 4. 核心步骤2:更新 Actor策略网络 (基于FB的隐空间Q值优化)
actor_metrics = update_Actor(obs, z)
# 5. 目标网络软更新 (τ:软更新系数)
soft_update(F_target, F, τ)
soft_update(B_target, B, τ)
return {**fb_metrics,**actor_metrics}
# -------------------- 核心1:FB网络更新 (Forward映射 + Backward映射) --------------------
def update_FB(obs, action, next_obs, discount, z):
# 无梯度计算目标值(用目标网络)
with no_grad():
next_action = Actor(next_obs, z).sample()
target_Fs = F_target(next_obs, z, next_action)
target_B = B_target(next_obs)
target_M = matmul(target_Fs, target_B.T)
target_M = aggregate_target(target_M, 悲观惩罚系数)
# 计算当前网络输出 & FB核心损失
Fs = F(obs, z, action)
B = B(next_obs)
M = matmul(Fs, B.T)
diff = M - discount * target_M
# FB核心损失:对角最大化匹配度 + 非对角最小化干扰
fb_loss = 非对角误差平方损失(diff) - 对角误差均值(diff)
# 反向映射B正交正则损失:约束B的正交性,提升泛化
fb_loss += α * orth_loss(B) # α:正则系数
# 可选Q值辅助损失:隐空间时序差分损失
fb_loss += β * q_loss(Fs, B, z, discount, target_Fs) # β:Q损失系数
# 梯度回传+更新F/B网络参数
optimize(fb_loss, F, B)
return {"fb_loss": fb_loss}
# -------------------- 核心2:Actor策略网络更新 --------------------
def update_Actor(obs, z):
# Actor采样动作 + 计算隐空间Q值 Q = (F*z).sum
action = Actor(obs, z).sample()
Fs = F(obs, z, action)
Q = (Fs * z).sum(dim=-1)
Q = aggregate_target(Q, 策略悲观系数)
# Actor损失:最大化隐空间Q值 → 损失取负均值
actor_loss = -mean(Q)
# 梯度回传+更新Actor参数
optimize(actor_loss, Actor)
return {"actor_loss": actor_loss}
# -------------------- 工具函数(极简抽象) --------------------
def soft_update(target_net, net, τ):
# 软更新公式:θ_target = τ*θ + (1-τ)*θ_target
target_net.params = τ * net.params + (1-τ) * target_net.params
def orth_loss(B):
# B的正交正则:协方差矩阵 对角趋近1,非对角趋近0
cov = matmul(B, B.T)
return 非对角协方差平方损失(cov) - 对角协方差均值(cov)方法局限性
人形机器人采用FBCPR算法的优势在于其天然具备动力学连续性,如BFM-Zero演示所示,动力学连续性使得机器人动作非常“友好”。
基于FB算法的无监督强化学习可能是人形机器人通用化的方向,但也需注意到目前该方法存在的局限性:
无监督是否能覆盖所有运动情况,取决于FB网络的大小,因为FB是一个理想概率空间下的近似投影。
由于FB原理导致动力学连续,因此难以泛化到不同动力学(FB会对所有观测动力学的未来占据状态分布取平均,不可避免导致策略表示干扰)。尽管实际过程中会对特征Z进行混合采样,能在一定程度上缓解该问题,但在动力学突变较大的情况下依然存在,这可能是in the air动作难以实现的原因。