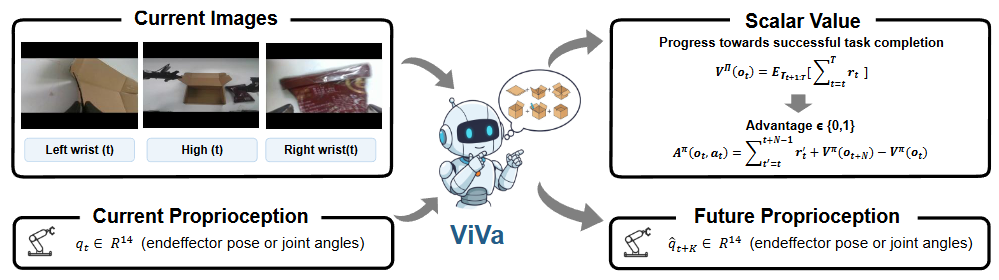
主题
视频生成价值模型 ViVa 开源 重构具身智能强化学习范式 VLA
在具身智能(Embodied AI)的演进中,VLA 模型的强化学习高度依赖价值模型(Value Model)的精准反馈。动作价值判定不仅是衡量任务成功的尺度,更是驱动策略自主进化的核心。然而,现有的评估体系大多依赖判别式的视觉语言模型(VLM)来判断任务进度。这类模型往往局限于静态特征的匹配,难以捕捉连续动作中的时空逻辑与物理约束。
极佳视界(GigaAI)发布了重磅成果ViVa (Video-generative Value model)。作为全球首个基于视频生成底座的价值评估模型,它不再仅仅是“看图打分”,而是通过“推演未来”来“评估当下”,为机器人装上了一个具备物理直觉的“预知大脑”。
日前,正式对外宣布ViVa的全面开源。
项目主页:https://viva-value-model.github.io/
代码:https://github.com/GigaAI-research/ViVa
论文:https://arxiv.org/abs/2604.08168
技术核心:以时空演化定义“价值”
ViVa 成功地将视频生成能力转化为价值函数,实现了从“静态识别”到“动态生成”的跨越:
时序先验注入:ViVa 以预训练的视频生成模型 Wan2.2 为底座, 通过捕捉连续的时序演化,有效地弥补了传统判别模型所面临的时空建模不足的问题。
物理逻辑内化:除了输出标量价值分数之外,ViVa 还会同时预测未来本体感知状态(Proprioception),通过在脑中想象物理过程的演变,模型实现了从捕捉视觉表象到理解物理规律的深层跨越。
潜空间状态表示:在潜空间内实现多视角视觉观测与本体状态的隐式对齐,建立了“以预演未来指导价值评估”的新准则,从底层逻辑上有效抑制了视觉幻觉。
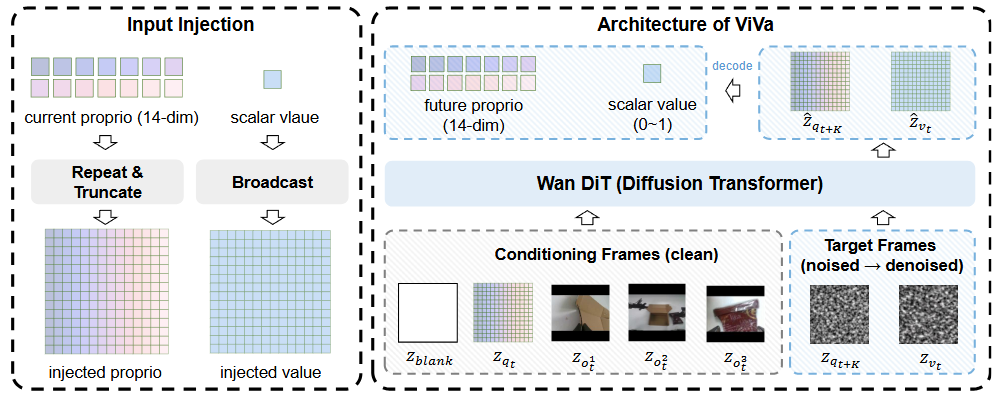
整体架构:基于流匹配的多目标生成建模
ViVa 打破了价值评估的传统框架,将其与机器人动力学推演联合建模为条件流匹配(Conditional Flow-matching)的生成任务。在此过程中,模型不再孤立地为图像打分,而是通过推演物理变化的过程中“感知”任务进度。
在架构层面,ViVa 基于 Wan2.2 时空底座,在潜空间内构建一系列多模态隐变量序列,分别包含:
条件帧 (Condition Frames):将当前的多视角观测与机器人本体状态共同表征为潜空间中的条件序列,为流匹配的去噪过程提供环境与状态约束。
目标帧 (Target Frames):基于流匹配机制,在潜空间中同时学习标量价值以及未来本体状态,同步产出任务进度与动力变化轨迹,引导模型的价值判断服从低层物理运动逻辑。
可视化分析:深挖物理规律,不仅是视觉匹配
对比 ViVa 与传统 VLM 在价值预测轨迹上的表现,我们可以清晰地看到,二者在物理理解层面存在显著的‘代沟’:
In-Domain(域内敏感):在纸箱组装任务上,ViVa 具备良好的细节感知,在有轻微偏移或者扣合不紧时,其价值就会急剧下降,说明 ViVa 可以从物理角度思考问题并能及时发现不合理的行为;但是传统的 VLM 对此无动于衷,在这种情况下数值依旧保持高位。
Out-of-Domain(跨域泛化):对于没见过的新物体(如叠裤子),ViVa 具有良好的迁移性。即便没见过的相关形变,也能依靠学到的物理先验去理解提拉、折叠等重要节点的价值跃迁。证明着 ViVa 已经从单纯地比对像素,对普遍性的物理演化规律有了正确的把握。
真机实验:集成 RECAP 的实战表现
我们在流程最为繁琐、难度最高的纸箱组装(Box Assembly)任务上,将 ViVa 集成到 RECAP 流程中进行了严苛的真机验证。该任务涉及抓取、放置、多侧翼折叠及最终扣合,是对价值评估模型的终极考验。
成功率飞跃:在 RECAP 框架加持下,ViVa将任务的成功率大幅提升至 73%。相比于传统的 VLM-based 价值模型,其成功率绝对值提升了 15%。
高效作业:得益于 ViVa 对任务状态极其精准的判断,机器人减少了无效动作与误判。系统的有效作业吞吐量提升至 14 次/小时。
ViVa 的推出是极佳视界对于下一代具身大模型的技术方向进行的深度思考:
从“判别式打分”到“生成式感知”,改变我们对价值判断的基本方式。传统的价值模型(Value Model)大多是判别式的回归,在复杂的、不断变化的真实世界中很容易造成视觉幻觉。我们认为,真正可靠的价值感知必须源于对物理演化的推演。
视频生成模型不仅是“模拟器”,也是“物理大脑”的先验来源。过去业内对于视频生成的研究主要集中在它对数据扩增所具有的仿真实用性上,而 ViVa 则提出一种新的思路,即将互联网上存在的普遍物理先验变成机器人的一种“直觉奖励”。这一步跨域能力的提炼是使机器人由“刻板复现”走到“物理泛化”的关键。
长程操控的突破点是“高频率并且准确”的稠密奖励循环。因为长程复杂的任务(例如纸箱拼装)难以实现的原因是由于奖励稀疏造成的搜索空间过大。而 ViVa 提供的生成式的价值增量,在底层构造一个非常高的一致性的、准确的稠密奖励信号。未来的大规模具身体感模型不再是纯粹端到端的黑盒,而是以具有物理常识的价值模型为“大脑”,不断纠正错误并且指引策略直至完成任务。