主题
备战TCEI 2026 (三) -- 人形机器人点球赛道
在机械臂和机械狗赛道之后,让我们一起来看一个比较有意思的赛道 -- 人形机器人点球赛道。
再次将官方的相关资料贴在下方:
另外可以参考比赛培训视频中关于题目和规则的部分:
从比赛文件中可以看出,我们需要的环境包括了:
- 源代码
- 九格大模型
- Unity(linux版本)
我们选择基础镜像:
由于镜像内的noVNC版本比较老,不支持直接复制粘贴,先参考这个文档升级VNC(https://www.gpufree.cn/docs/guide/know_issue/novnc_clipboard.html)。
源代码
由于源代码在百度网盘,我们还是先安装百度网盘客户端。
我们可以在百度网盘客户端下载页面下载对应版本的客户端。 或者直接执行:
bash
# 安装4.17.7版本,是当前最新版本。未来可能会有更新。
cd /root/gpufree-data/
wget https://039ede-1874119700.antpcdn.com:19001/b/pkg-ant.baidu.com/issue/netdisk/LinuxGuanjia/4.17.7/baidunetdisk_4.17.7_amd64.deb
dpkg -i baidunetdisk_4.17.7_amd64.deb下载源代码点球赛.7z: 
将源代码压缩包下载到/root/gpufree-data/目录下:
bash
cd /root/gpufree-data/
# 解压源代码 点球赛.7z
7z x "点球赛.7z"
mv 点球赛-fixed/Unity-RL-Playground-main /root/gpufree-data/inference/
rm -rf 点球赛-fixed最终形成如下路径:
/root/gpufree-data/inference/
|--Unity-RL-Playground-main
|--9G7B_MHA安装九格大模型
新建一个单独的conda虚拟环境来处理。系统已经安装了conda,我们直接创建虚拟环境
bash
# 创建一个名为inference的conda环境
conda create -n inference python=3.10中间可能需要输入几次回车和 y 或者 a。
安装依赖、下载大模型并解压:
bash
# 激活inference环境
conda activate inference
# 解压大模型
tar -xvf 9G7B_MHA.tar -C /root/gpufree-data/inference/
# 安装pytorch==2.9.1,由他的依赖自动选择torchvision
pip install torch==2.9.1 torchvision --index-url https://download.pytorch.org/whl/cu128
# vllm版本和transform版本虽然不匹配,但是可以运行
pip install vllm
pip install transformers==4.44.0 \
datamodel-code-generator \
accelerate \
jsonschema \
pytrie \
sentencepiece \
protobuf \
datamodel-code-generator==0.32.0 \
bitsandbytes \
fastapi \
uvicorn
# 清理pip缓存节约系统盘
pip cache purge下载九格大模型
bash
# 在数据盘创建inference文件夹
mkdir -p /root/gpufree-data/inference
# 下载大模型
cd /root/gpufree-data
wget https://thunlp-model.oss-cn-wulanchabu.aliyuncs.com/9G7B_MHA.tar
tar -xvf 9G7B_MHA.tar -C /root/gpufree-data/inference/测试大模型推理
bash
# 创建测试脚本
conda activate inference
cd /root/gpufree-data/inference/
vim test_inference.py贴入如下代码:
python
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
if __name__ == "__main__":
model_path = "/root/gpufree-data/inference/9G7B_MHA" # 如果没有按照文档组织路径,需要修改为实际路径
prompt = "山东最高的山是?"
tokenizer = AutoTokenizer.from_pretrained(model_path,
trust_remote_code=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.to(device)
model.eval()
prompt = tokenizer.apply_chat_template(conversation=[{"role": "user",
"content": prompt}], add_generation_prompt=True, tokenize=False)
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(model.device)
with torch.no_grad():
res = model.generate(**inputs, max_new_tokens=256)
responses = tokenizer.decode(res[0][inputs.input_ids.shape[1]:],
skip_special_tokens=True)
ai_answer = responses.strip()
print(ai_answer)执行测试脚本:
bash
# 激活inference环境
conda activate inference
cd /root/gpufree-data/inference/
python test_inference.py得出以下结果即说明推理正常: 
仿真程序
创建ubuntu用户
因为Unity/团结引擎不能在root用户下运行,所以我们需要创建一个普通用户来运行。
bash
# 创建一个普通用户ubuntu
useradd -m -s /bin/bash ubuntu
# 设置ubuntu用户的密码,建议设置为gpufree
passwd ubuntu输入两遍密码后,继续执行以下命令:
bash
# 一、给与ubuntu关键目录权限
usermod -aG sudo ubuntu
# 创建软连接,将我们的数据盘挂载到ubuntu用户下
ln -s /root/gpufree-data /home/ubuntu/gpufree-data
# 注意,由于云环境是一次性的,所以这些开放权限的问题不涉及安全问题。
# 如果是在本地环境,建议整体环境都在非root下执行。
# 给/home/ubuntu目录添加可执行权限
chmod 777 /tmp
chmod 777 /home/ubuntu
# 给/root目录添加可执行权限
chmod 777 /root
# 转移gpufree-data的owner
chown -R ubuntu:ubuntu /root/gpufree-data
# 改变/home/ubuntu目录的所有者和所属组为ubuntu
chown ubuntu:ubuntu /home/ubuntubash
# 二、给与桌面权限
# 1. 复制root的X11认证信息给ubuntu用户
cp /root/.Xauthority /home/ubuntu/.Xauthority
chown ubuntu:ubuntu /home/ubuntu/.Xauthoritybash
# 三、其他相关权限
# 以下内容主要方便来回切换启动用户启动其他软件。
# 如果非常的了解linux以及相关依赖和权限问题,可以酌情忽略。
# 允许ubuntu访问/opt目录(通常安装软件的地方)
chmod 755 /opt
# 允许ubuntu访问/usr/local目录
chmod 755 /usr/local
# 创建共享工具目录
mkdir -p /usr/local/shared
chmod 777 /usr/local/shared
# 设置.bashrc共享(可选)
cp /root/.bashrc /home/ubuntu/.bashrc
chown ubuntu:ubuntu /home/ubuntu/.bashrc安装
由于unity和团结引擎在linux下安装比较复杂。建议在阅读文档后逐步操作,而不是复制粘贴。 由于团结引擎不需要VPN,本文以介绍团结引擎为主。 首先前往团结引擎官网注册账户:团结引擎官网
bash
# 设置默认浏览器为firefox
xdg-settings set default-web-browser firefox.desktop
update-alternatives --install /usr/bin/x-www-browser x-www-browser /usr/bin/firefox 200 && \
update-alternatives --set x-www-browser /usr/bin/firefox && \
xdg-settings set default-web-browser firefox.desktop && \
export BROWSER=/usr/bin/firefox && \
# 下载安装
cd /root/gpufree-data
mkdir tuanjie
wget https://public-cdn.tuanjie.cn/hub/prod/tuanjiehub-amd64.deb
dpkg -i tuanjiehub-amd64.deb切换到ubuntu用户,启动unity hub
bash
su - ubuntu
# 启动unity hub
unityhub打开页面后,登录或者注册一个账户。
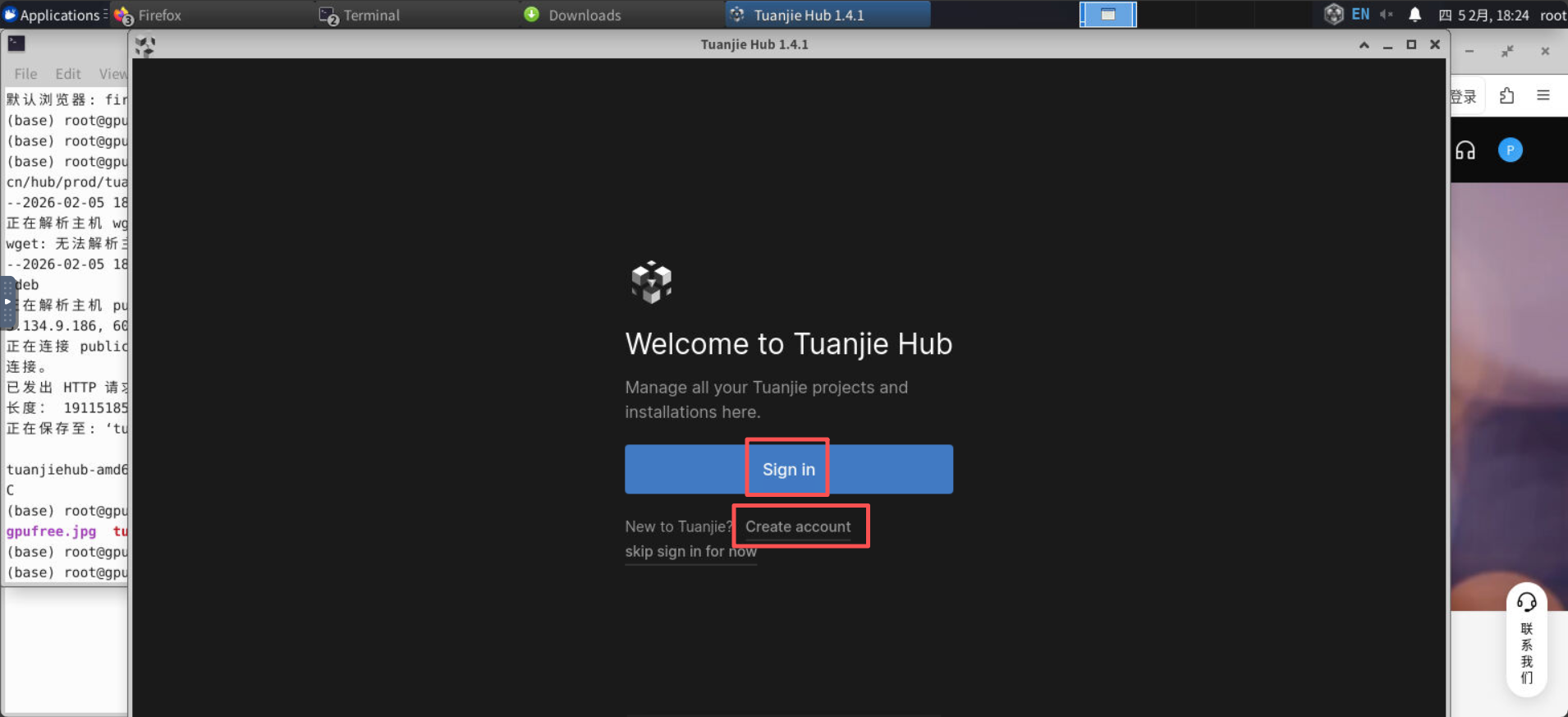
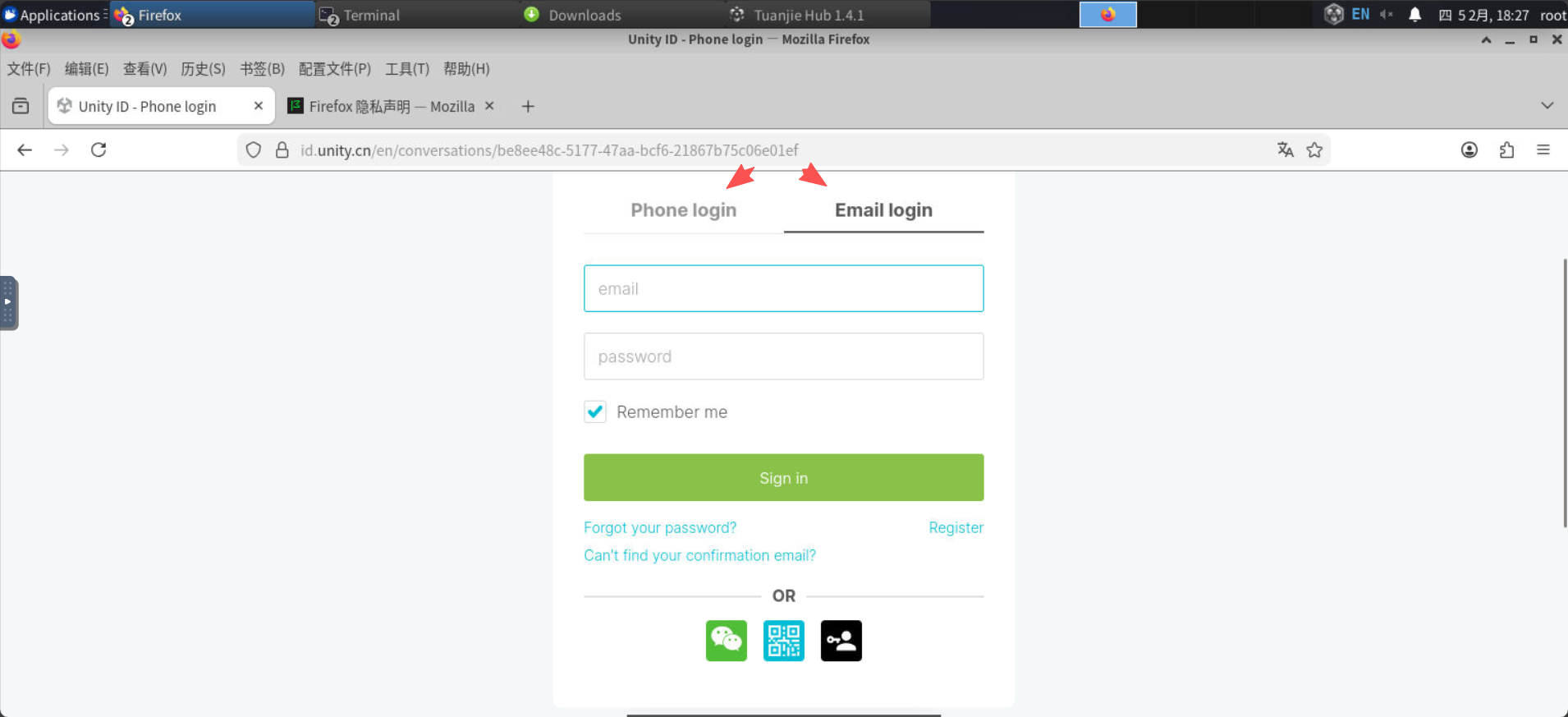
登录,并按照自己注册的方式登录。 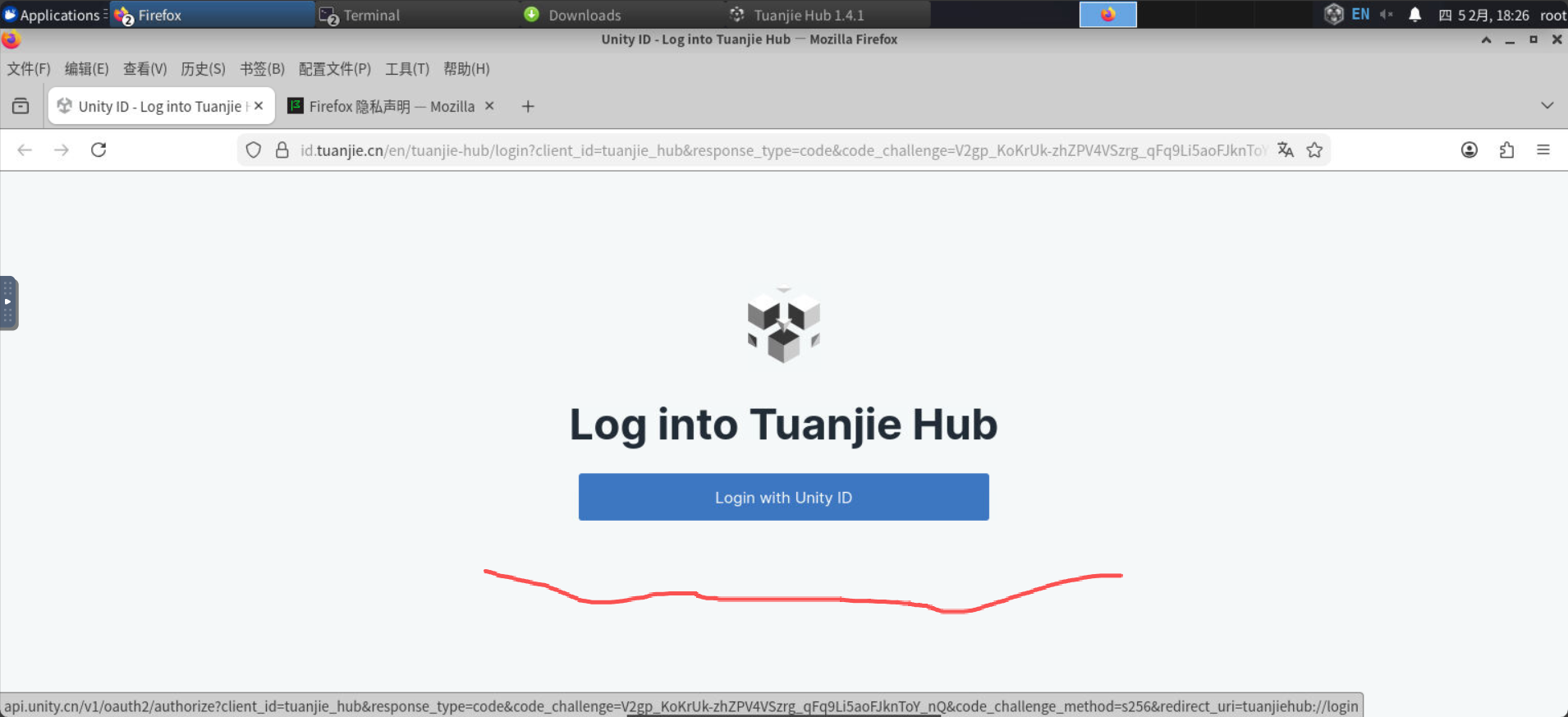
使用团结hub安装团结引擎: 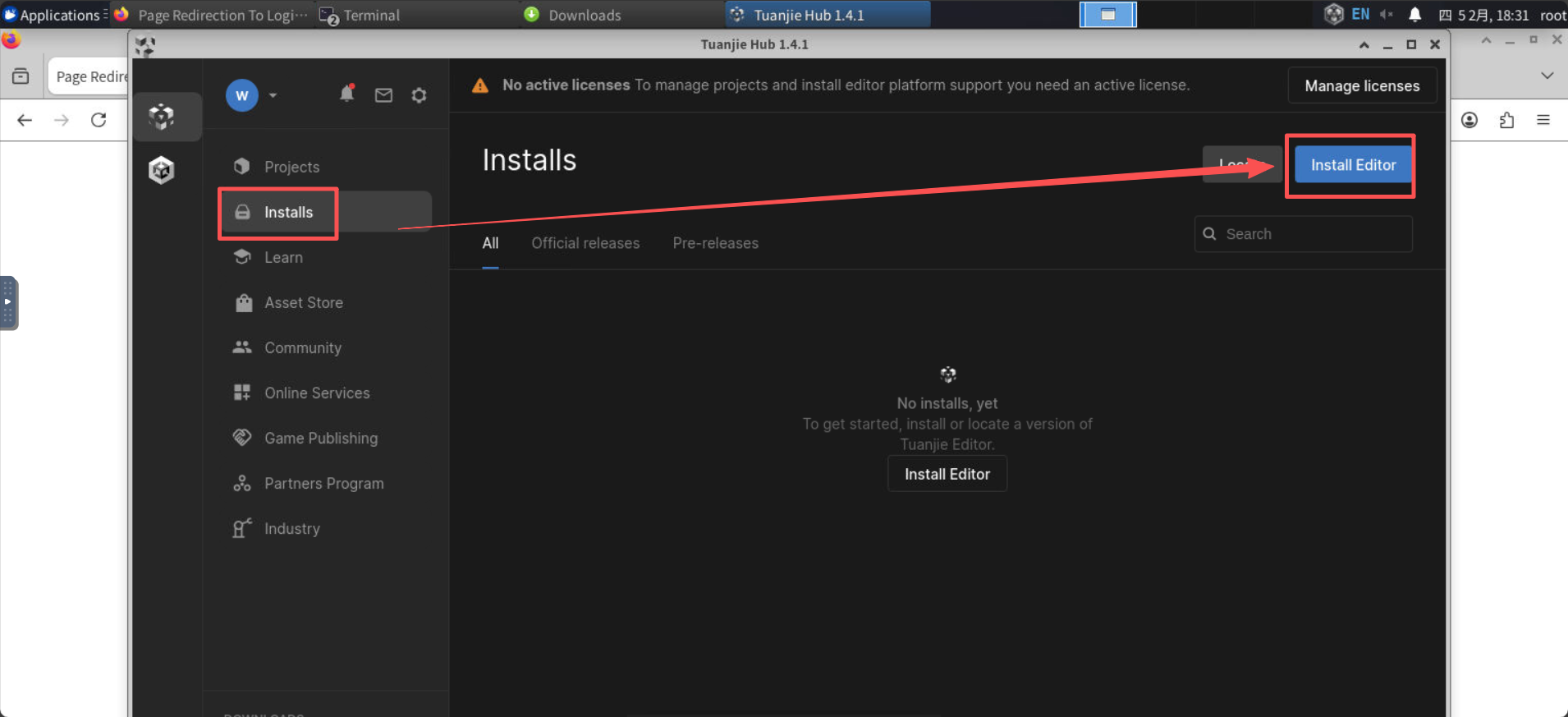 ,选择LTS版本。
,选择LTS版本。
其中将安装位置设定在我们创建的/home/ubuntu/gpufree-data/tuanjie/目录下。
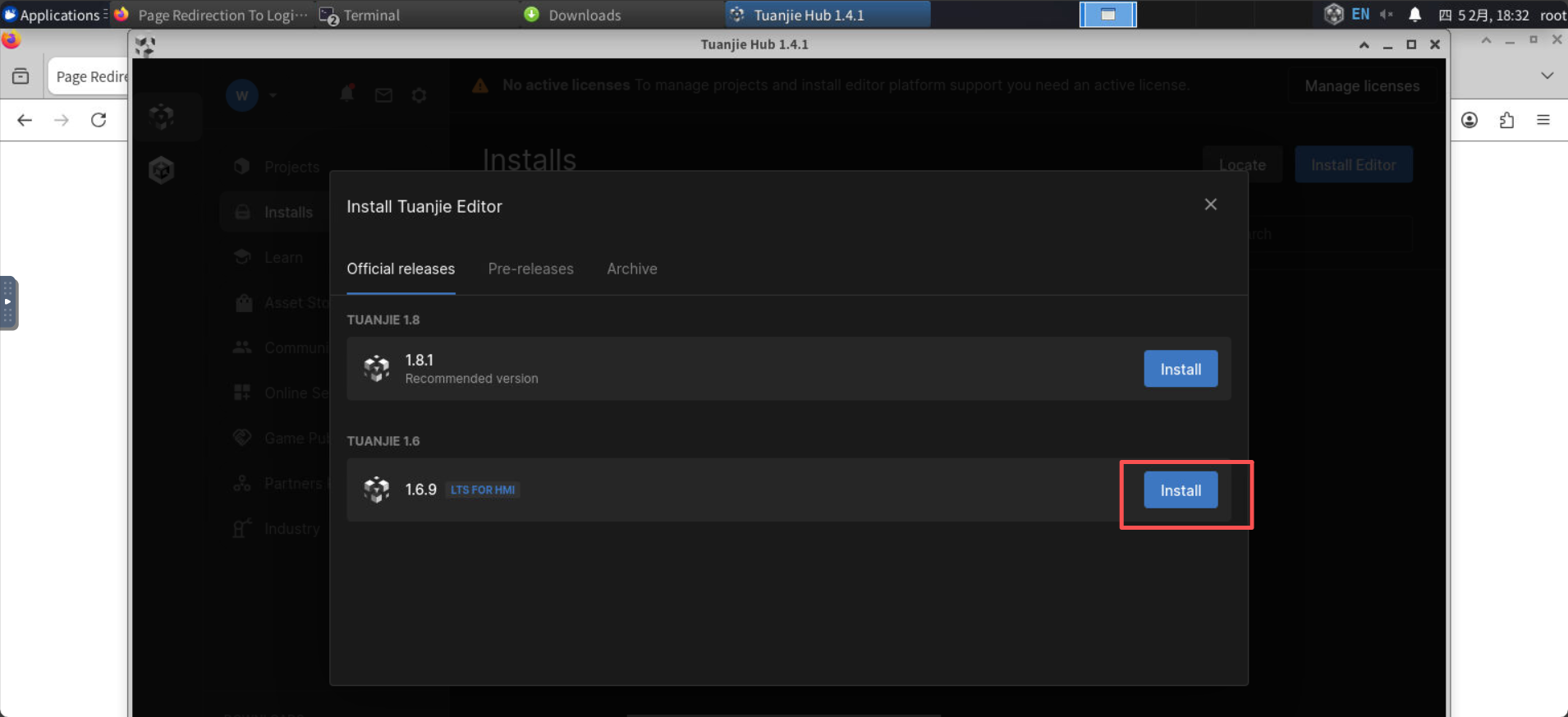
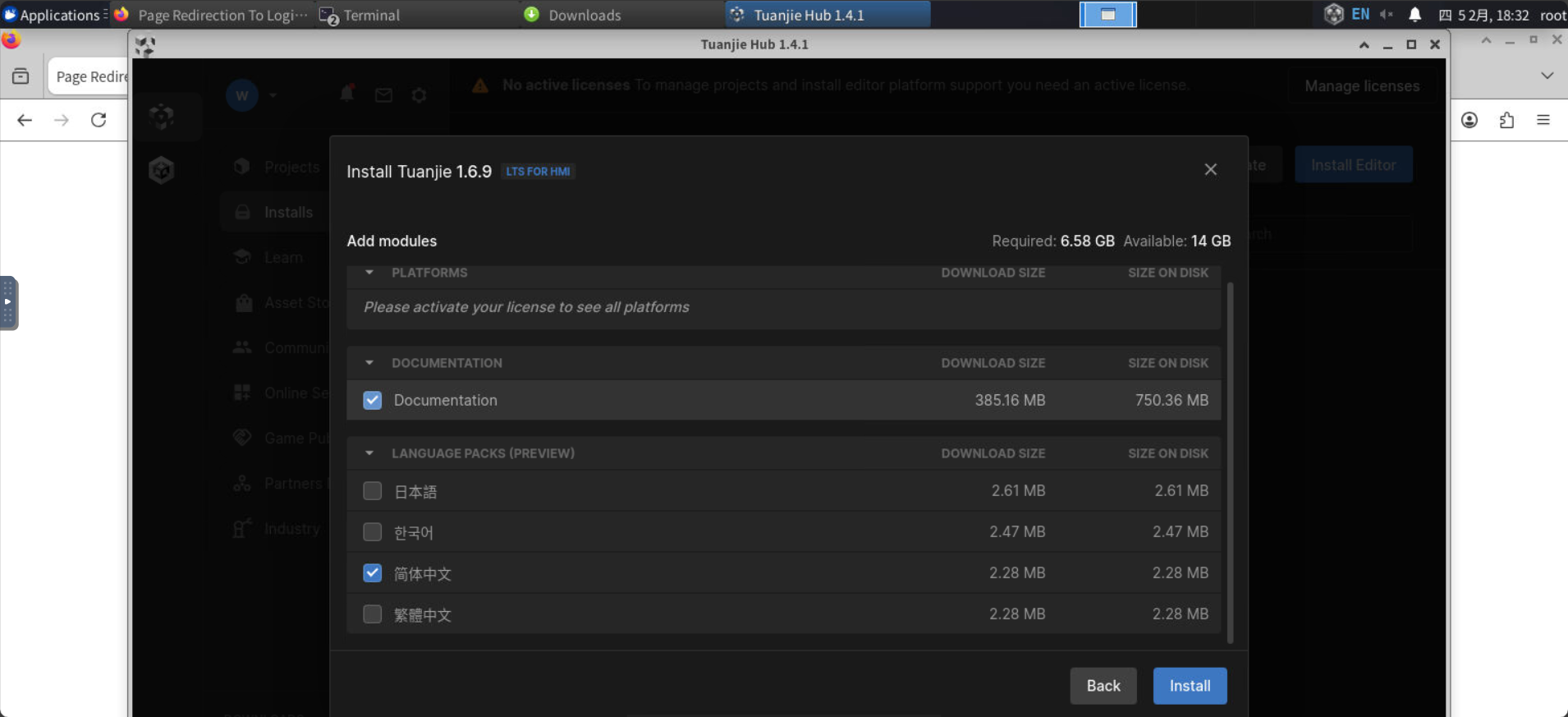
安装的同时,我们创建一个免费的license, 点击manager license: 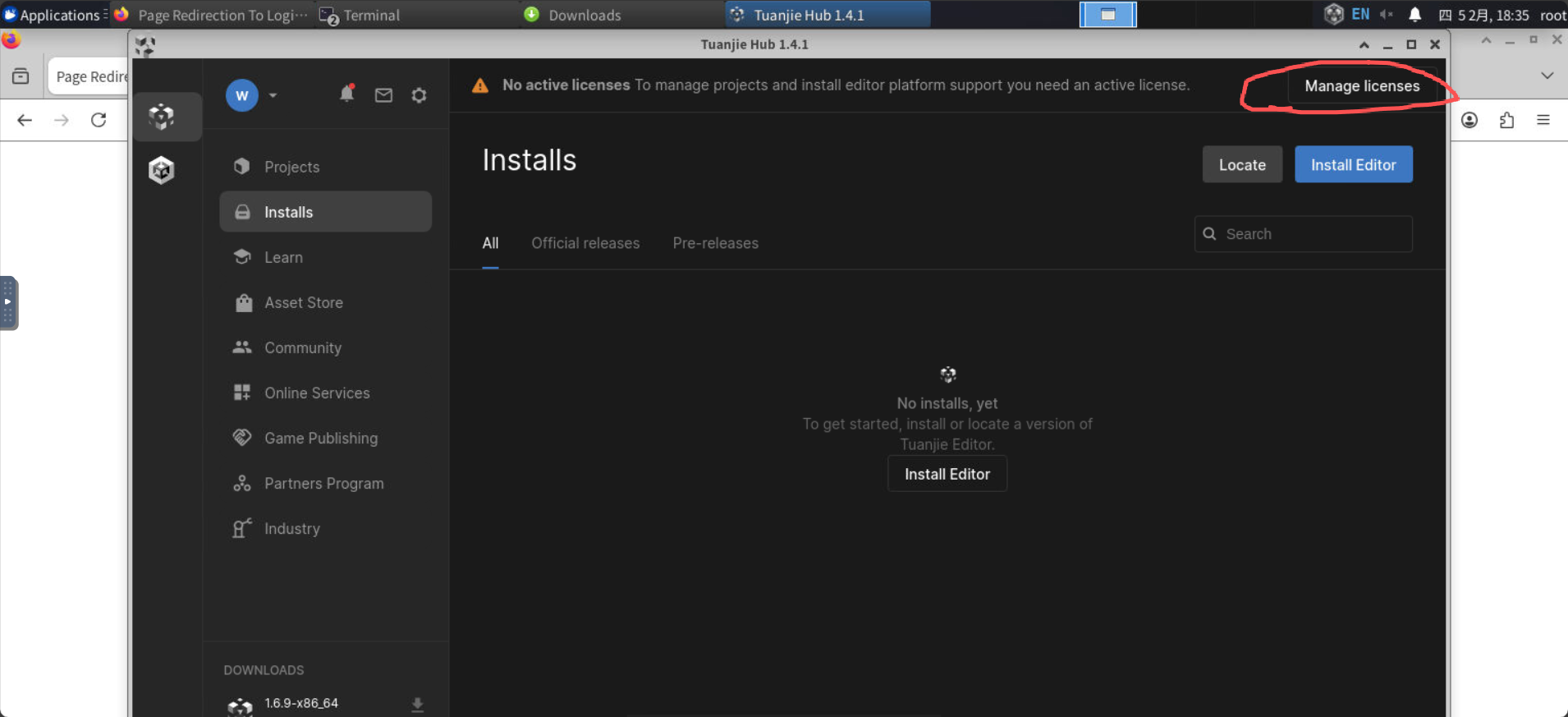
同意条款创建免费license。
然后将下载的点球项目导入团结引擎,选择左侧project,打开 /home/ubuntu/gpufree-data/inference/Unity-RL-Playground-main 目录: 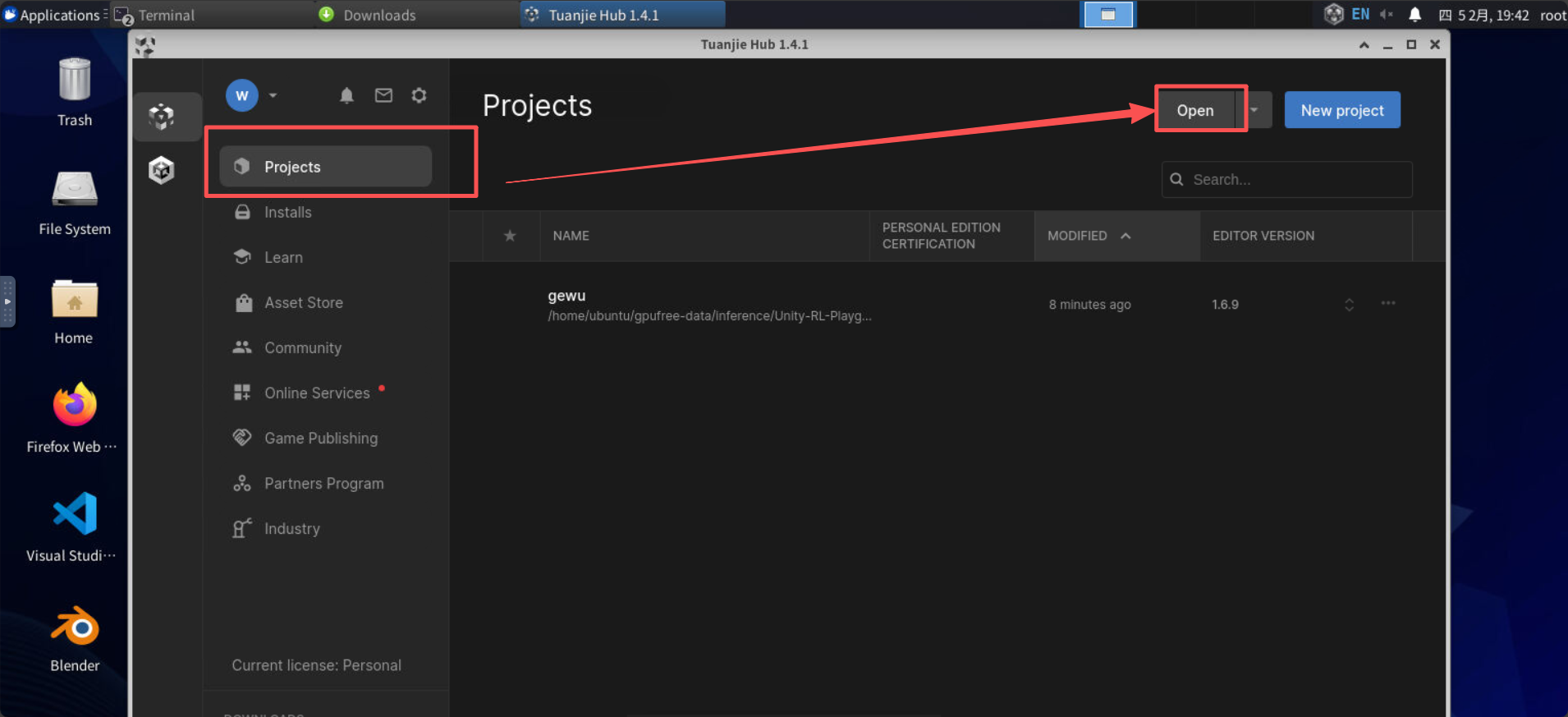
单机项目,首次启动后,可能会转换版本,需要等待转换完成后打开。 
至此所有基础环境搭建完成。
启动大模型api服务
比赛方预备三个大模型api文件,可以在这个百度网盘找到:大模型api文件
把这三个文件放在/home/ubuntu/gpufree-data/inference/目录下,
bash
cd /home/ubuntu/gpufree-data/inference/
conda activate inference
# 修改fast_api_inference.py第55行,将模型路径修改为:/home/ubuntu/gpufree-data/inference/
sed -i '55s|/home/sun/sdb/temp/CPM-9G-8B/9Gmodel/|/root/gpufree-data/inference/|' fast_api_inference.py
# 修改最后一行,将ip改为0.0.0.0
sed -i 's|10.21.22.23|0.0.0.0|' fast_api_inference.py
# 启动服务
python fast_api_inference.py测试大模型api服务是否正常:
bash
# 另开一个终端
# 测试大模型api服务是否正常
curl -X GET "http://127.0.0.1:8080/health"
# 如下显示即为成功
> {"status":"healthy","message":"模型已加载并准备就绪"}环境完全搭建完毕后,即可开始比赛。
量化模型
量化模型的完整代码位于 /root/gpufree-data/inference/fast_api_inference_LH.py:
bash
# 执行量化模型代码:
conda activate inference
python fast_api_inference_LH.py量化代码核心参数参考如下表格:
| 参数名称 | 可选值 | 核心作用 | 推荐场景与使用建议 |
|---|---|---|---|
| load_in_4bit | True / False(默认False) | 启用4-bit动态量化,将模型权重压缩为4位存储,显存占用直接降低75%(对比FP32) | 显存严重受限场景(如消费级GPU运行7B+模型);若显存充足且追求极致精度,可设为False |
| bnb_4bit_quant_type | "nf4"(推荐) / "fp4" (默认"nf4") | 控制量化算法,决定权重的4位表示方式:- nf4:NormalFloat4,基于权重正态分布优化,信息论最优- fp4:自定义浮点数4位,计算效率更高 | 精度敏感场景(如文本生成、复杂推理)选nf4;对精度要求低、追求极限速度选fp4 |
| bnb_4bit_use_double_quant | True / False(默认False) | (默认False) | 开启“嵌套量化”(双重量化),对已量化的权重系数二次压缩 |
| bnb_4bit_compute_dtype | torch.float16 / torch.bfloat16 | 控制计算时的反量化精度(4bit权重解码后参与运算的数据类型) | 英伟达Ampere架构及以后显卡(如RTX30/40系列、A100)选torch.bfloat16(硬件优化);老显卡(如RTX 20系列)选torch.float16 |
量化后显存占用只有不到6GB,但相应的量化后会降低推理性能。
更多信息
至此只有源文档的宇树机器人相关接口了,此接口使用与平台没有联系,可以参考百度网盘中的点球赛场景应用挑战赛使用手册.pdf中的如下章节。 