主题
通用机器人基础模型————π0.7 技术深度解读报告 VLA
一、研究背景:从"专用专家"到"通用通才"
1.1 机器人控制的老大难问题
过去十年,机器人领域最主流的范式是"一个任务、一个模型"——为每项具体任务(如折叠衬衫、制作咖啡)单独收集数据、训练专门的专家模型。这种方式在特定任务上能达到很高的成功率,但其代价是泛化能力极差:换一个新的厨房布局、一个新的物体形态、甚至换一台不同品牌的机械臂,模型往往就"傻眼"了。
这背后的根本矛盾在于:现实世界的任务是无穷无尽的,但可收集的训练数据永远是沧海一粟。
1.2 大模型浪潮中的机器人学
以 GPT-4、Claude 为代表的大语言模型,在虚拟世界(文字、代码、推理)展现了惊人的组合泛化能力——模型可以将学到的知识重新组合,解决从未见过的复杂问题。这一能力来源于大规模预训练中的多样化数据和通用表示学习。
Physical Intelligence(π)团队敏锐地捕捉到了这一思路的潜力:从 2024 年的 π0,到 2025 年的 π*0.6、π0.5,再到今天发布的 π0.7,这家公司始终在探索一个问题:

二、Π0.7 是什么?
2.1 一句话定义
Π0.7 是一个可引导(Steerable)的通用视觉-语言-动作(VLA)模型,能够通过多样化的多模态提示,在不同机器人、不同场景、不同技能之间执行灵巧操作任务——无需针对新任务重新训练。
2.2 核心关键词解读
| 关键词 | 含义 |
|---|---|
| 可引导(Steerable) | 模型的行为可以通过外部提示(语言、元数据、视觉子目标)来控制和引导,而不仅仅是执行固定的动作序列 |
| 涌现能力(Emergent Capabilities) | 模型展现出训练数据中从未明确出现过的能力——通过组合已有技能来解决新问题 |
| 通用(Generalist) | 一个模型覆盖多种任务、多种机器人、多种场景,而非专用专家 |
| 灵巧操作(Dexterous Manipulation) | 涉及双臂协调、手部精细控制的任务,如折叠衣物、抓取小型物体等 |
2.3 团队背景
作者列表达到惊人的 118 位,涵盖了机器人学顶会 most influential 人物:
Chelsea Finn(斯坦福副教授,机器人学习领域标杆人物)
Sergey Levine(UC Berkeley 教授,深度强化学习与机器人结合的先驱)
Karol Hausman(Google Brain 出身,机器人基础模型倡导者)
Brian Ichter、Danny Driess(Google DeepMind → π 的核心成员)
三、技术架构:从提示工程到组合智能
3.1 整体架构图
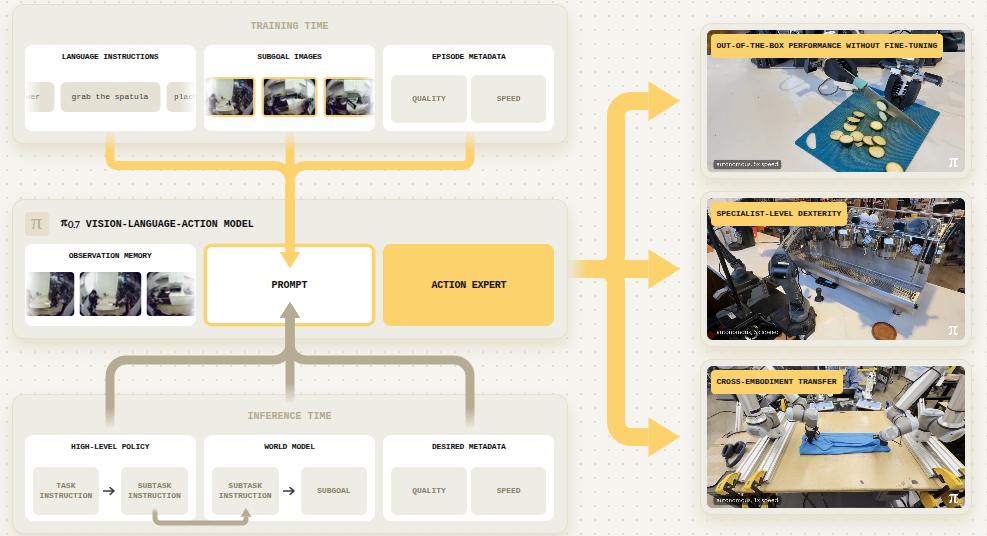
图 1:Π0.7 VLA 模型架构图。顶部为四类多模态输入(语言指令、元数据、控制模态、视觉子目标),中间为 VLA 模型核心(含观察记忆、高层策略、世界模型、动作专家),底部输出机器人动作。
3.2 多样化条件训练(Diverse Conditioning)——核心创新
这是 π0.7 最关键的技术创新,作者称之为 "多样化的上下文是组合泛化的关键"。
3.2.1 传统 VLA 的提示结构
传统的视觉-语言-动作模型,提示通常是单一的:
纯语言指令:"把杯子放在桌子上"
模型只需理解"做什么",不需要理解"怎么做"
3.2.2 Π0.7 的多模态提示结构
π0.7 在训练时使用了四种提示模态,这使得训练数据的多样性被充分释放:
| 提示模态 | 内容示例 | 作用 |
|---|---|---|
| 语言指令 | "拿起隔热手套"、"打开抽屉"、"将锅放在炉灶上" | 指定任务目标和子步骤 |
| 回合元数据 | Quality(质量优先)、Speed(速度优先) | 指定执行策略偏好 |
| 控制模态标签 | joint(关节控制)/ effector(末端执行器控制) | 指定控制方式 |
| 视觉子目标图像 | 显示子步骤完成时的空间布局 | 提供空间参考 |
3.2.3 数据来源的三驾马车
plaintext
训练数据来源
│
├── 来自不同机器人的遥操作数据
│ ↓
│ (不同形态、不同控制方式、不同场景)
│
├── 人类视频数据(无动作标签)
│ ↓
│ (扩展视觉先验,学习人类行为模式)
│
└── 自主收集的 Episode 数据
↓
(通过运行各种策略收集,包含成功和失败经验)这三种数据源的叠加,使得 π0.7 的训练数据在机器人类型、任务类型、执行策略三个维度上都有极高的多样性。
3.3 世界模型:连接高层规划与低层控制
π0.7 架构中引入了一个轻量级 世界模型(World Model),负责在推理时:
接收高层策略的指令 → 将任务拆解为子目标
生成视觉子目标图像 → 用一张"目标画面"描述子任务的完成状态
- 将子目标图像反馈给动作专家 → 动作专家以当前观察 + 子目标图像生成具体动作
plaintext
高层任务指令
│
↓
高层策略(High-Level Policy)
│
↓
子任务指令(Subtask Instruction)
│
├──→ 动作专家(直接执行)
│
└──→ 世界模型(World Model)
│
↓
视觉子目标图像(Subgoal Image)
│
↓
动作专家(Action Expert)
│
↓
机器人动作3.4 观察记忆(Observation Memory)
模型在推理过程中维护一个 观察记忆,使得机器人能够:
跟踪长时序任务中的状态变化
在多步骤任务中保持上下文一致性
处理需要"返回检查"的任务(如:先打开冰箱 → 取出食材 → 关闭冰箱)
四、核心能力深度解析
4.1 组合泛化(Compositional Generalization)
4.1.1 什么是组合泛化?
组合泛化是指:模型能够将从不同任务中学到的子技能,以新的方式组合起来,解决从未见过的新任务。
举例来说:
模型学会了"打开抽屉",也学会了"拿起锅铲"
但从未学过"从抽屉里拿出锅铲"这个具体组合
π0.7 可以零样本完成这个组合任务
4.1.2 空气炸锅实验:最有力的证据
这是 π0.7 论文中最震撼的演示:
实验设定:
训练数据中从未有过空气炸锅的任何数据
最接近的数据:仅有两段"关闭空气炸锅"的演示片段,以及 DROID 数据集中 Frnaka 机械臂的类似操作数据
实验 1 — 零样本(无任何指导)
提示:"load a sweet potato into the air fryer"(将红薯放入空气炸锅)
结果:做出合理尝试,部分完成但未完全成功
实验 2 — 逐步语言指导(类似教练模式)
提供逐步语言指导,类似引导人类使用新电器的过程
结果:任务执行更加有效
实验 3 — 高层策略微调后完全自主
对高层策略进行轻量微调,使其自动生成语言子目标
结果:完全自主执行,无需遥操作
4.1.3 提示即技能
一个值得注意的发现:任务的成功与否,往往取决于提示的质量,而不只是模型本身。在空气炸锅实验中,通过优化提示词(加入具体的放置位置、动作顺序等),成功率可以从极低跃升到接近 95%。
这引出了一个重要观点:π0.7 将"任务定义"从训练阶段迁移到了推理阶段。传统方式是"训练定义任务",而 π0.7 是"提示定义任务"——同一个模型,通过不同的提示,可以执行完全不同的技能组合。
4.2 跨实体迁移(Cross-Embodiment Transfer)
4.2.1 实验设计
| 对比维度 | 源机器人(训练数据) | 目标机器人(零样本) |
|---|---|---|
| 机器人类型 | 静态双臂机器人 | 双臂 UR5e 系统 |
| 臂重/惯量 | 轻量 | 沉重(惯量大) |
| 夹爪 | 高精度专用夹爪 | Robotiq 平行夹爪(精度较低) |
| 训练数据 | 375 小时折叠衣物数据 | 零数据 |
两种机器人在尺寸、定位和形态上差异显著,π0.7 必须采用完全不同的抓取策略和运动规划。
4.2.2 结果
π0.7 在双臂 UR5e 上的折叠衣物成功率,与有 375 小时遥操作经验的人类专家的零样本成功率相当。
4.2.3 为什么跨实体迁移这么难?
在 π0.7 之前,跨实体迁移是机器人领域的公认难题,主要原因有:
运动学差异:不同机器人的自由度、关节限位、臂长完全不同
动力学差异:惯量、摩擦力、抓取力的差异使得相同的动作在不同机器人上产生不同效果
- 传感器差异:相机安装位置、视角、分辨率的不同导致视觉特征的巨大差异
π0.7 的解法:大规模的多样化数据训练 + 多模态条件提示。当模型见过的机器人类型足够多,它就会学会"在运动学和动力学差异中寻找不变量"——这些不变量,就是技能的抽象表示。
4.3 专家级性能:通用模型 vs 专用模型
这是 π0.7 最令人印象深刻的基准测试结果:
| 任务 | 吞吐量(归一化) | 成功率 | 对比专用 RL 专家 |
|---|---|---|---|
| 折叠衣物(T恤和短裤) | 1.5× | ~100% | 达到或超越 |
| 折叠衣物(最难物品) | 2.0× | ~100% | 超越 |
| 制作浓缩咖啡 | 1.5× | ~100% | 达到 |
| 组装盒子 | 2.0× | ~100% | 超越 |
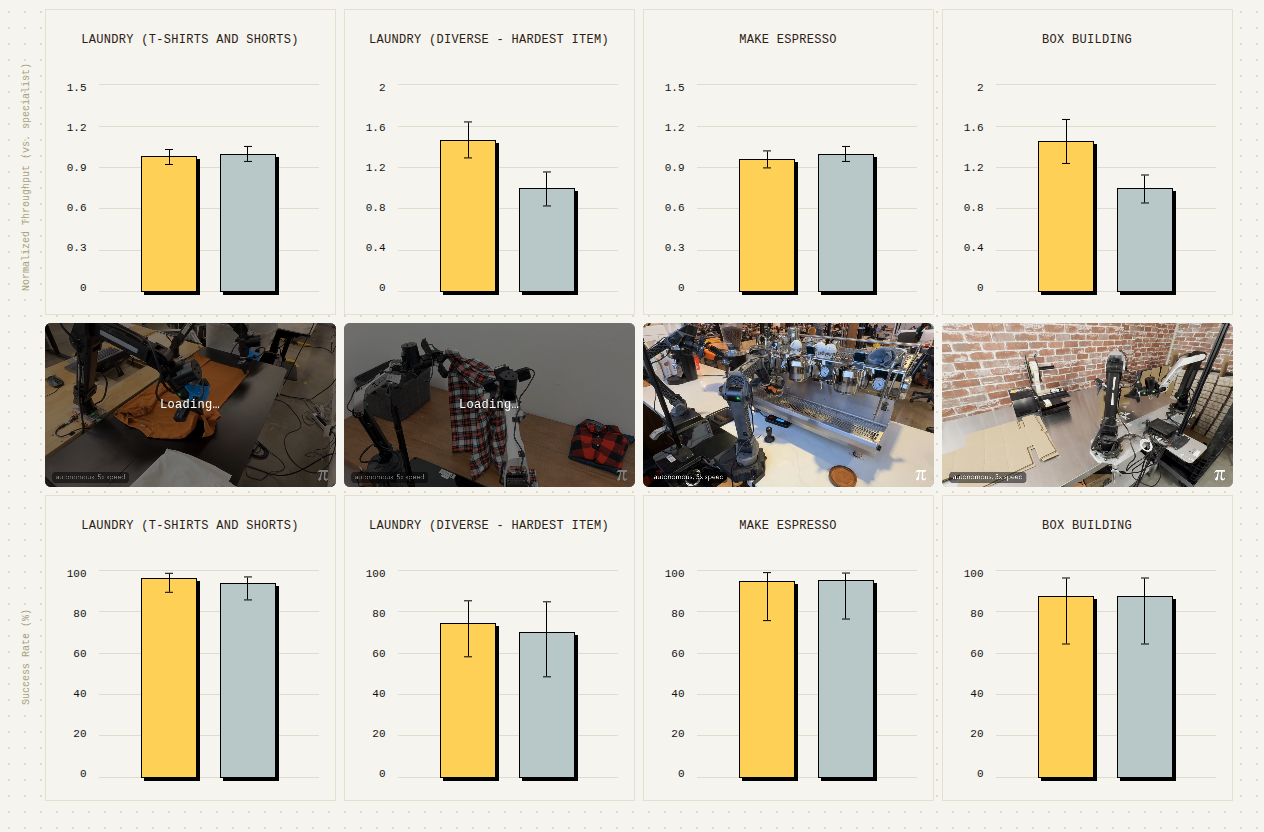
2:单一 π0.7 通用模型 vs 专用 RL 专家策略性能对比。归一化吞吐量(Y轴)显示,π0.7 在四项任务(折叠衣物、制作咖啡、组装盒子)上均达到或超越专门针对各任务训练的专家模型。
这意味着什么?意味着大规模预训练的复合效应——当数据量和多样性足够大时,模型不仅能泛化到新任务,还能在已有任务上追上甚至超越专门优化的专家模型。
五、技术溯源:从 π0 到 π0.7 的演进路径
5.1 π 系列模型技术演进
plaintext
时间线
│
├─ 2024年10月 ──┤ π0 (arXiv: 2410.24164)
│ 视觉-语言-动作流模型
│ 验证了"一个VLA模型控制多种机器人"的可行性
│
├─ 2025年 ──────┤ π0.5
│ 开放世界泛化
│ 移动双臂机器人清理全新房间
│
├─ 2025年11月 ──┤ π*0.6 (arXiv: 2511.14759)
│ 从经验中学习(强化学习微调)
│ 专门针对双臂灵巧操作优化
│
└─ 2026年4月 ───┤ π0.7 (本期解读)
多样化条件训练
组合泛化 + 跨实体迁移
可引导的通用模型5.2 每一代的核心突破
| 代际 | 核心问题 | 核心创新 | 代表能力 |
|---|---|---|---|
| π0 | 如何用一个模型控制多种机器人? | 流匹配(Flow Matching)+ 多机器人数据协同训练 | 7种机器人统一控制 |
| π0.5 | 如何泛化到完全开放的新环境? | 扩展预训练 + 移动双臂平台 | 清理从未见过的房间 |
| π*0.6 | 如何在专家水平上执行精细操作? | RL 微调 + 专家策略蒸馏 | 衣物折叠、咖啡制作等高精度任务 |
| π0.7 | 如何组合技能解决未训练任务? | 多样化条件训练(Diverse Conditioning) | 零样本新任务执行 + 跨实体迁移 |
5.3 与同期工作的对比
2026年,机器人VLA领域正处于"军备竞赛"阶段:
| 模型 | 机构 | 核心特点 | 与 π0.7 的差异 |
|---|---|---|---|
| HEX | 斯坦福/帝国理工 | 人形全身VLA,Sim-to-Real | 聚焦人形机器人平台 |
| Touch Dreaming | 字节跳动 | 触觉感知VLA | 强调触觉模态 |
| Genesis | 乔治亚理工 | 通用机器人基础模型 | 开源生态更强 |
| π0.7 | Physical Intelligence | 组合泛化 + 跨实体迁移 | 强调通用性和可引导性 |
六、深度思考:这项工作意味着什么?
6.1 从"机器人技能"到"机器人智能"的范式转变
长期以来,机器人领域的主流范式是:先定义任务 → 收集数据 → 训练模型 → 部署。这一范式的根本局限在于——任务空间是开放的,无法穷举。
π0.7 代表了一种新的范式转变:
这与大语言模型的能力涌现逻辑高度相似:不是在每个具体任务上训练,而是在足够多样的任务上预训练,然后通过提示解锁新能力。
6.2 "提示工程"在机器人学中的崛起
π0.7 的一个反直觉发现:机器人的表现高度依赖提示的质量。在空气炸锅实验中,通过精心设计逐步语言指导,可以将成功率从个位数提升到接近 95%。
这带来了一个新的研究方向:机器人的"提示工程学"——如何用自然语言精准描述任务,如何将复杂任务分解为可引导的子目标。这与 LLM 时代的 Prompt Engineering 一脉相承,但增加了物理世界的复杂性。
6.3 Scaling Law 是否适用于机器人学?
Sergey Levine 在接受 TechCrunch 采访时表示:
如果这一假设成立,π0.7 可能只是开始——随着训练数据量级的进一步提升(从 thousands 到 millions of hours),机器人基础模型的能力可能会出现质的飞跃。
6.4 局限性与未解问题
尽管 π0.7 取得了令人瞩目的进展,研究团队也坦诚地指出了当前的局限:
无法完全自主:π0.7 目前仍需要人类的逐步指导("教练模式"),无法仅凭一句高级指令完成复杂多步骤任务
提示质量瓶颈:当人类无法准确描述任务执行方式时,模型表现受限
缺乏标准化基准:目前缺乏统一的机器人泛化能力评估标准,跨论文对比困难
硬件依赖:π0.7 的测试主要在实验室环境,真实家庭/工业场景的表现尚待验证
- 安全性:组合泛化带来的"意外能力"也意味着潜在的安全风险——模型可能会尝试开发者未预期的动作
七、展示任务一览
根据官方页面,π0.7 展示的任务包括:
| 序号 | 任务类型 | 技能要素 |
|---|---|---|
| 1 | 拿起隔热手套 | 单臂精确抓取 |
| 2 | 打开抽屉 | 抽屉铰链操作 |
| 3 | 拿取锅铲 | 细长物体抓取 |
| 4 | 将锅放在炉灶上 | 多步骤空间规划 |
| 5 | 折叠毛巾 | 双臂协调 + 布料操作 |
| 6 | 擦拭台面 | 接触丰富的操作 |
| 7 | 关闭冰箱 | 门/盖类物体操作 |
| 8 | 削蔬菜 | 精细刀工操作 |
| 9 | 用清洁剂擦玻璃 | 接触力控制 |
| 10 | 折叠T恤(UR5e) | 跨实体迁移验证 |
九、资源导航
十、总结
π0.7 是 Physical Intelligence 在通用机器人基础模型道路上的重要一步。它的核心贡献不在于某一单项指标的刷新,而在于证明了:
这一能力的涌现,预示着机器人领域正在从"专项技能积累"向"通用智能涌现"的转折点。但正如团队所言,这仍是"早期但有意义的步骤",距离真正的通用机器人仍有关键挑战待解。
文章来源:Mbot具身智能实验室杰西