主题
Dexbotic调研:模块化VLA开源工具箱 VLA
Dexbotic调研:模块化VLA开源工具箱
在复杂的物理世界中执行任务,机器人需要同时具备三种能力:敏锐的视觉感知、强大的逻辑认知、以及精细的运动控制。在过去,这三者往往被杂糅在一个极其厚重的黑盒网络中,不仅训练成本高昂,且任何单一模块的改进都需要对整个系统进行重构。
Dexbotic 是由 Dexmal 团队开源的 Vision-Language-Action (VLA) 模型工具箱,基于 PyTorch 构建,专为具身智能(Embodied AI)研究而设计。 Dexbotic 2.0 直击这一痛点,在业界率先实现了 V(Vision Encoder,视觉编码器)、L(LLM,大语言模型)、A(Action Expert,动作专家)的彻底模块化解耦。
github地址:https://github.com/dexmal/dexbotic
感谢Mbot具身智能实验室hq同学对本文的研究与供稿支持
主要解决的问题——数据标准化,环境解耦,算法前沿化
VLA 领域的研究分散在各个机构,各自使用不同的深度学习框架和模型架构。这种差异给用户比较不同策略带来了很大麻烦——他们需要配置多套实验环境和数据格式,开发流程非常繁琐。此外,难以确保每个被比较的策略都被充分优化,导致比较结果不公平。
比如:开发者如果想对比 $\pi_0$ 和 CogACT,可能需要配置两个完全不同的 Conda 环境,甚至要处理不同的 Python 版本冲突,Dexbotic 的核心逻辑是“统一抽象”。它把不同的算法逻辑封装进统一的接口,就像给不同的电器配上了万能转换插头。
另一个问题是,许多现有 VLA 模型是基于过时的视觉语言模型(VLM)构建的,导致大多数用户无法受益于最新先进的 VLM。Dexbotic 的优势在于它的模块化架构。当社区出现更强的 VLM(如 Qwen-VL、Llama-3-Vision 或最新的 SigLIP)时,用户可以相对轻松地把这些“新引擎”换到 VLA 的“底盘”上,而不需要重写动作生成模块。
主要应用场景
- 机器人操作与导航 核心目标是开发能够完成机器人操作的模型,涵盖三个能力:视觉理解(处理机器人摄像头的 RGB 图像)、语言理解(解析自然语言任务描述)、动作生成(通过基于流的扩散去噪生成精确的机器人动作)。
- 主流机器人硬件部署 针对 UR5、Franka、ALOHA 等主流机器人,Dexbotic 提供统一的训练数据格式和部署脚本。
- VLA 算法研究与复现 内置多种主流 VLA 模型的环境配置,允许用户通过简单设置即可复现、微调和推理前沿 VLA 算法(如 π0、CogACT 等)。
- RL 后训练强化 已支持 RLinf 作为 RL 后训练后端,结合 VLA + 强化学习推进研究与应用。
Dexbotic 特点
Dexbotic是一个开源的VLA模型工具箱,旨在简化具身智能领域中VLA模型的开发、优化和比较。通过提供统一的框架,Dexbotic将VLM和动作专家(AE)模块化,支持多种VLA策略的复现,并能在单一环境下进行实验配置。工具箱提供强大的预训练模型,有效提升VLA策略的性能,解决了多样化的模型架构和实验环境配置问题。
关键特点
统一数据格式: 无论你是用 ALOHA 还是 UR5 采集的数据,进到这里都转换成标准格式。
统一训练与部署: 它内置了从数据预处理、分布式预训练、微调(Fine-tuning)到实机部署(Deployment)的全流程脚本。
统一模块化框架:Dexbotic将VLA模型分为VLM和AE两部分,VLM负责处理视觉和文本数据,生成多模态标记;AE则基于这些标记生成动作序列。通过标准化结构,Dexbotic简化了不同策略的对比和优化过程。
强大预训练模型:Dexbotic引入自研的DexboticVLM,优于传统的Llama2等模型,显著提升了VLA策略的效果。该模型支持离散和连续动作生成,用户可直接使用预训练模型进行训练或微调。
实验驱动开发框架:Dexbotic通过Exp脚本实现灵活的实验配置。用户可以通过修改脚本中的参数来调整实验设置,快速开发新策略,极大提升了实验的灵活性和可扩展性。云端与本地训练支持:Dexbotic支持在阿里云等大规模云平台进行训练,同时也可在本地使用RTX4090等消费级GPU进行训练,满足不同规模的用户需求。
多平台机器人部署:Dexbotic支持多种主流机器人平台(如UR5、Franka等),并采用统一的数据格式(Dexdata),确保不同平台的数据兼容性。开源的部署脚本可根据用户需求定制。
预训练模型:Dexbotic提供离散和连续两种预训练模型,分别适用于不同VLA任务。
Dexbotic-Base是为离散VLA策略设计的预训练模型,支持离散标记生成机器人动作;
Dexbotic-CoqACT等连续模型通过引入动作专家(AE)预测连续动作。这些模型已基于多个真实和模拟数据集进行训练,适应多种机器人任务。实验层:Dexbotic的实验层采用模块化配置,允许用户快速开发和测试不同VLA策略。实验脚本的灵活性使得用户可以根据不同任务和策略,修改模型、数据和训练参数,轻松进行定制化实验。
Dexbotic 核心特性与架构概览
Dexbotic 是一个专为具身智能(Embodied AI)设计的开源视觉-语言-动作(VLA)模型工具箱。其核心设计理念在于通过模块化和标准化的流程,加速机器人策略的开发与部署。
一、 核心功能特性 (Main Features)
- 统一模块化 VLA 框架:兼容主流开源大模型接口,深度集成了具身操控(Manipulation)与导航(Navigation)任务,并预留了全身控制(Whole-body Control)接口。
- 强力预训练基座模型:开源了基于 Pi0 和 CogACT 等架构的高性能预训练模型,在 SimplerEnv、CALVIN 等仿真环境及真实机器人任务中表现卓越。
- 以实验为中心的开发模式:采用“分层配置 + 工厂注册 + 入口调度”的设计。用户仅需修改
Exp脚本即可快速调整模型或任务,遵循“开闭原则”,兼顾系统的灵活性与稳定性。 - 全场景训练支持:适配性极强,既支持阿里云、火山引擎等大规模云端训练,也兼容 RTX 4090 等消费级显卡的本地训练需求。
- 广泛的硬件兼容性:支持 UR5、Franka、ALOHA 等主流机器人平台,提供统一的数据格式与通用部署脚本。
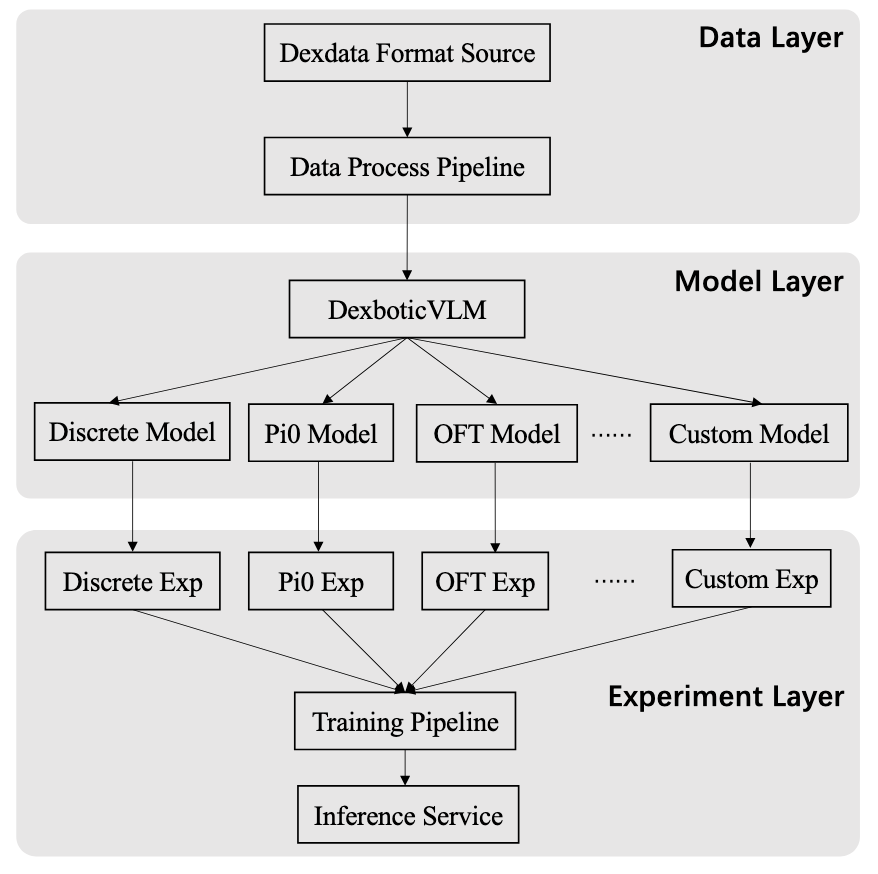
二、 系统架构组成 (Basic Components)
Dexbotic 代码库由以下三大核心板块构成:
| 板块 | 核心职责 | 详细说明 |
|---|---|---|
| Data (数据) | 数据加工与转换 | 支持多种机器人原始数据的处理,并统一转换为 Dexdataset 标准格式。 |
| Model (模型) | 算法核心实现 | 实现各类 VLA 方法,包含视觉编码器(Vision Encoders)与投影器(Projectors)等关键组件。 |
| Exp (实验) | 配置与调度管理 | 提供默认实验配置。通过继承 base_exp(定义优化器、模型、训练器等基础参数)生成特定策略脚本(如 ABC_exp)。 |
三、 工作流闭环
该框架通过 训练流水线 (Training Pipeline) 实现模型的高效迭代,并通过 推理服务 (Inference Service) 完成从算法到实体的落地,构建了从数据处理到策略部署的完整技术闭环。