主题
实战指南| Linkerhand-unidexgrasp 快速实现灵巧手仿真项目复现 灵巧手
本文讨论了灵巧手抓取仿真项目复现与调参技巧,涵盖项目复现、理论讲解、参数解读等多方面内容。关键要点包括:
- 项目复现技巧:介绍 Linkerhand-unidexgrasp 项目复现,如环境配置、gpufree 平台复现、抓取提案生成复现、教师 PPO 策略训练等,涉及 Python、CUDA、pytorch 版本确定及相关软件安装。
- unidexgrasp 理论讲解:阐述基础概念如 SO(3)/SO(2) 旋转群与李群、CVAE、ImplicitPDF 等,介绍两阶段架构及数据流,分析实验结果,证明解耦旋转、TTA、状态规范化、物体课程学习等的有效性。
- 抓取提案生成参数解读:说明核心流程、数据准备、模型训练、监控、评估、可视化与数据转换等内容,给出快速开始命令。
一、Linkerhand-unidexgrasp项目复现技巧分享,如何避免大多数报错
1.1 环境配置的基本思路
确定Python版本
根据Python选择大致的CUDA版本,如(python3.6对应CUDA 10.x, python3.8对应CUDA 11.x, python3.10对应CUDA 12.x)
有任何升降CUDA的情况,请尽量在云平台进行项目复现,尽量不要在本地电脑上进行,或者请使用docker镜像
确定了CUDA版本,再根据说明文档提示或者询问AI,确定合适的pytorch版本,到官网进行搜索并下载
接着按照说明文档的步骤进行,遇到的问题与解决方法请及时进行记录
1.2 gpufree平台复现
1.isaacgym安装
- gpufree平台链接:https://www.gpufree.cn/images
镜像选择如下:
- 显卡选择4090,云平台的系统盘偏小,请把缓存和下载移动到
~/gpufree-data/数据盘:
bash
# 1. 设置 conda 缓存到 gpufree-data(避开 /opt 限制)
conda config --add pkgs_dirs ~/gpufree-data/conda_pkgs
mkdir -p ~/gpufree-data/conda_pkgs
# 2. 设置临时目录也到这儿
export TMPDIR=~/gpufree-data/tmp
mkdir -p $TMPDIR- 倘若遇到空间不足,可以参照官方帮助文档:https://www.gpufree.cn/docs/guide/data_disk/clear_sysdisk.html 进行简单清理:
bash
# 1. 清理 conda 缓存(释放已下载的损坏包)
conda clean -a -y
# 2. 清理 /tmp 目录(解压临时文件占用空间)
rm -rf /tmp/conda* /tmp/tmp*下载isaacgym并上传到
~/gpufree-data/目录下软件要求
Python 3.8
CUDA 11.8
查看当前CUDA版本
plain text
nvcc --version
#或者执行
nvidia-smi- 将CUDA降至11.8并安装满足要求的pytorch版本
bash
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run \
--silent \
--toolkit \
--installpath=/usr/local/cuda-11.8 \
--no-opengl-libs \
--no-drm
# 环境变量(写入 ~/.bashrc,如果有旧 cuda 路径先删掉)
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda-11.8
source ~/.bashrc
# 验证
nvcc -V # 应显示 11.8
which nvcc # 应指向 /usr/local/cuda-11.8/bin/nvcc
echo $CUDA_HOME # 应输出 /usr/local/cuda-11.8- 压缩包上传至~/gpufree-data, 解压isaacgym压缩包,
bash
# 解压到当前目录(或指定目标目录)
tar -xzf IsaacGym_Preview_4_Package.tar.gz
# 验证解压成功后删除原压缩包
rm IsaacGym_Preview_4_Package.tar.gz- 创建虚拟环境并安装isaacgym
bash
conda create -n dexgrasp python=3.8 -y
conda activate dexgrasp
cd ~/gpufree-data/isaacgym/python
python -m pip install -e .
# 基础依赖
pip install PyQt5 numpy urdfpy- 测试isaacgym安装成功
matlab
cd ~/gpufree-data
git clone https://github.com/linker-bot/linkerhand-sim.git
cd linkerhand-sim/linker_hand_isaac_gym_urdf
# 确保 conda lib 优先(解决 libpython3.8.so 找不到)
export LD_LIBRARY_PATH=/opt/conda/envs/dexgrasp/lib:$LD_LIBRARY_PATH
python isaac_urdf.py2.抓取提案生成的复现
创建虚拟环境
bash
conda create -n unidexgrasp python=3.8
conda activate unidexgrasp安装依赖
bash
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
python -c "import torch; print(torch.__version__); print(torch.version.cuda)"
# 应显示 1.10.0+cu113 和 11.3
conda install -y https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch3d/linux-64/pytorch3d-0.6.2-py38_cu113_pyt1100.tar.bz2
cd /root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker
pip install -r requirements.txt
cd thirdparty/pytorch_kinematics
pip install -e .
cd ../nflows
pip install -e .
# CSDF已存在于 /.../dexgrasp_policy_l20hand/CSDF
# 需移动至 /.../dexgrasp_generation_forlinker/thirdparty/CSDF
cd ../CSDF
cd ../../
# 降级 setuptools 到兼容版本
pip install setuptools==58.0.4
# 额外安装 distutils 兼容包(如果上面不行)
pip install packaging
pip install ipdb
export BROWSER=firefox路径修改
bash
# 将generation部分的文件夹下datasets文件夹中的
# shadow_hand_builder.py文件中第35行的mjcf_path参数改为data/mjcf下
# 存放的shadow_hand.xml文件的路径
def __init__(self,
mesh_dir="/root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker/data/mjcf/meshes",
mjcf_path="/root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker/data/mjcf/shadow_hand.xml"):
# 将configs/dataset文件夹除eval_data.yaml文件之外的
# 其余四个文件的第一行root_path后面的参数全部修改为
# generation部分项目文件夹下(mini)data文件夹的路径
root_path: "/root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker/mini_generation"
#将/tests下可视化的三个.py文件中的object_mesh路径进行替换,./mini_generation/DFCData/meshes/core文件结构修改
bash
# mini_generation/DFCData/meshes下缺少一层core文件夹。在core文件下再放四个物体文件
/root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker/mini_generation/DFCData/meshes/core/bottle-1a7ba1f4c892e2da30711cdbdbc73924
# 修改下列行以配合mini_generation的数据 /root/gpufree-data/linkerhand-unidexgrasp-main/dexgrasp_generation_forlinker/datasets/dex_dataset.py代码修改
python
def get_file_list(self, root_dir, splits_data, splits, categories):
"""
:param root_dir: e.g. "./data"
:return: e.g. ["./data/DFCData/bottle/poses/1a7ba1f4c892e2da30711cdbdbc73924/00000.npz", ...]
or ["./data/DFCData/poses/bottle/1a7ba1f4c892e2da30711cdbdbc73924/00000.npz"]
"""
file_list = []
item_class = []
missing_instances = []
empty_instances = []
for category in categories:
for split in splits:
for instance in splits_data[category][split]:
name = instance.split('-')[0]
# print(name)
# 检查 name 是否已经存在于 self.item_class 中
if name not in item_class:
# 如果是新名称,添加到 self.item_class 列表中
item_class.append(name)
file_dir_path = pjoin(root_dir, self.dataset_cfg["dataset_dir"], "datasetv4.1", category, instance)
if not os.path.isdir(file_dir_path):
missing_instances.append(file_dir_path)
continue
files = list(filter(lambda file: file[0] != "." and (file.endswith(".npz")),
os.listdir(file_dir_path)))
if len(files) == 0:
empty_instances.append(file_dir_path)
continue
files = list(map(lambda file: pjoin(file_dir_path, file),
files))
file_list += files
# print("aaaaa", item_class)
if missing_instances:
preview = ", ".join(missing_instances[:3])
suffix = " ..." if len(missing_instances) > 3 else ""
print(f"Skipped {len(missing_instances)} missing split instances under datasetv4.1: {preview}{suffix}")
if empty_instances:
preview = ", ".join(empty_instances[:3])
suffix = " ..." if len(empty_instances) > 3 else ""
print(f"Skipped {len(empty_instances)} empty split instances with no .npz labels: {preview}{suffix}")
print(f"Split {splits}: {len(file_list)} pieces of data.")
return file_listpython
"""
Last modified date: 2022.08.07
Author: mzhmxzh
Description: dataset
"""
import os
import json
import numpy as np
import torch
import trimesh as tm
import transforms3d
from torch.utils.data import Dataset
import pytorch3d.ops
def has_mesh_assets(mesh_dir):
return (
os.path.isdir(mesh_dir)
and os.path.isfile(os.path.join(mesh_dir, 'poses.npy'))
and os.path.isfile(os.path.join(mesh_dir, 'pcs_table.npy'))
)
def resolve_mesh_dir(data_root_path, object_code):
candidate_dirs = [
os.path.join(data_root_path, object_code),
os.path.join(data_root_path, os.path.basename(object_code)),
]
for mesh_dir in candidate_dirs:
if has_mesh_assets(mesh_dir):
return mesh_dir
return None
def list_mesh_object_codes(data_root_path):
object_codes = []
if not os.path.isdir(data_root_path):
return object_codes
for entry in os.listdir(data_root_path):
entry_path = os.path.join(data_root_path, entry)
if has_mesh_assets(entry_path):
object_codes.append(entry)
continue
if not os.path.isdir(entry_path):
continue
for child in os.listdir(entry_path):
child_path = os.path.join(entry_path, child)
if has_mesh_assets(child_path):
object_codes.append(os.path.join(entry, child))
return object_codes
class Meshdata(Dataset):
def __init__(self, cfg, mode):
self.mode = mode
self.data_root_path = os.path.join(cfg['dataset']['root_path'], 'DFCData', 'meshes')
self.splits_path = os.path.join(cfg['dataset']['root_path'], 'DFCData', 'splits')
self.object_code_list = []
for splits_file_name in os.listdir(self.splits_path):
with open(os.path.join(self.splits_path, splits_file_name), 'r') as f:
splits_map = json.load(f)
self.object_code_list += [os.path.join(splits_file_name[:-5], object_code) for object_code in splits_map[mode]]
self.object_list = []
for object_code in self.object_code_list:
mesh_dir = resolve_mesh_dir(self.data_root_path, object_code)
if mesh_dir is None:
continue
pose_matrices = np.load(os.path.join(mesh_dir, 'poses.npy'))
pcs_table = np.load(os.path.join(mesh_dir, 'pcs_table.npy'))
# for scale in [0.06, 0.08, 0.1, 0.12, 0.15]:
# indices = np.random.permutation(len(pose_matrices))[:cfg['n_samples']]#对于每个缩放尺度,随即选择n_samples个旋转矩阵。
# for index in indices:
# pose_matrix = pose_matrices[index]
# pose_matrix[:2, 3] = 0
# self.object_list.append((object_code, pcs_table[index], scale, pose_matrix))
for scale in [0.1]:
indices = np.random.permutation(len(pose_matrices))[:cfg['n_samples']]#对于每个缩放尺度,随即选择n_samples个旋转矩阵。
for index in indices:
pose_matrix = pose_matrices[index]
pose_matrix[:2, 3] = 0
self.object_list.append((object_code, pcs_table[index], scale, pose_matrix))
def __len__(self):
return len(self.object_list)
def __getitem__(self, idx):
object_code, pcs_table, scale, pose_matrix = self.object_list[idx]
object_pc = torch.from_numpy(scale * (pcs_table @ pose_matrix[:3, :3].T + pose_matrix[:3, 3]))
only_object_pc = object_pc[:3000]
table_pc = object_pc[3000:]
max_diameter = 0.2
n_samples_table_extra = 2000
min_diameter = (only_object_pc[:, 0] ** 2 + only_object_pc[:, 1] ** 2).max()
distances = min_diameter + (max_diameter - min_diameter) * torch.rand(n_samples_table_extra, dtype=torch.float) ** 0.5
theta = 2 * np.pi * torch.rand(n_samples_table_extra, dtype=torch.float)
table_pc_extra = torch.stack([distances * torch.cos(theta), distances * torch.sin(theta), torch.zeros_like(distances)], dim=1)
table_pc = torch.cat([table_pc, table_pc_extra])
table_pc_cropped = table_pc[table_pc[:, 0] ** 2 + table_pc[:, 1] ** 2 < max_diameter]
table_pc_cropped_sampled = pytorch3d.ops.sample_farthest_points(table_pc_cropped.unsqueeze(0), K=1000)[0][0]
object_pc = torch.cat([only_object_pc, table_pc_cropped_sampled])
plane = torch.zeros_like(torch.from_numpy(pose_matrix[2]))
plane[2] = 1
#plane = pose_matrix[2].copy()
#plane[3] *= scale
ret_dict = {
"object_code": object_code,
"obj_pc": object_pc,
"plane": plane,
"scale": scale,
}
return ret_dict
class Meshdata_mypc(Dataset):
def __init__(self, cfg, mode):
self.mode = mode
self.data_root_path = os.path.join(cfg['dataset']['root_path'], 'DFCData', 'meshes')
# self.splits_path = os.path.join(cfg['dataset']['root_path'], 'DFCData', 'splits')
# self.data_root_path = cfg['dataset']['root_path']
# self.object_code_list = []
# for splits_file_name in os.listdir(self.splits_path):
# with open(os.path.join(self.splits_path, splits_file_name), 'r') as f:
# splits_map = json.load(f)
# self.object_code_list += [os.path.join(splits_file_name[:-5], object_code) for object_code in
# splits_map[mode]]
self.object_code_list = list_mesh_object_codes(self.data_root_path)
self.object_list = []
for object_code in self.object_code_list:
mesh_dir = resolve_mesh_dir(self.data_root_path, object_code)
if mesh_dir is None:
continue
pose_matrices = np.load(os.path.join(mesh_dir, 'poses.npy'))
pcs_table = np.load(os.path.join(mesh_dir, 'pcs_table.npy'))
# for scale in [0.06, 0.08, 0.1, 0.12, 0.15]:
# indices = np.random.permutation(len(pose_matrices))[:cfg['n_samples']]#对于每个缩放尺度,随即选择n_samples个旋转矩阵。
# for index in indices:
# pose_matrix = pose_matrices[index]
# pose_matrix[:2, 3] = 0
# self.object_list.append((object_code, pcs_table[index], scale, pose_matrix))
for scale in [0.1]:
indices = np.random.permutation(len(pose_matrices))[:cfg['n_samples']] # 对于每个缩放尺度,随即选择n_samples个旋转矩阵。
for index in indices:
pose_matrix = pose_matrices[index]
pose_matrix[:2, 3] = 0
self.object_list.append((object_code, pcs_table[index], scale, pose_matrix))
def __len__(self):
return len(self.object_list)
def __getitem__(self, idx):
object_code, pcs_table, scale, pose_matrix = self.object_list[idx]
object_pc = torch.from_numpy(scale * (pcs_table @ pose_matrix[:3, :3].T + pose_matrix[:3, 3]))
only_object_pc = object_pc[:3000]
table_pc = object_pc[3000:]
max_diameter = 0.2
n_samples_table_extra = 2000
min_diameter = (only_object_pc[:, 0] ** 2 + only_object_pc[:, 1] ** 2).max()
distances = min_diameter + (max_diameter - min_diameter) * torch.rand(n_samples_table_extra,
dtype=torch.float) ** 0.5
theta = 2 * np.pi * torch.rand(n_samples_table_extra, dtype=torch.float)
table_pc_extra = torch.stack(
[distances * torch.cos(theta), distances * torch.sin(theta), torch.zeros_like(distances)], dim=1)
table_pc = torch.cat([table_pc, table_pc_extra])
table_pc_cropped = table_pc[table_pc[:, 0] ** 2 + table_pc[:, 1] ** 2 < max_diameter]
table_pc_cropped_sampled = pytorch3d.ops.sample_farthest_points(table_pc_cropped.unsqueeze(0), K=1000)[0][0]
object_pc = torch.cat([only_object_pc, table_pc_cropped_sampled])
plane = torch.zeros_like(torch.from_numpy(pose_matrix[2]))
plane[2] = 1
# plane = pose_matrix[2].copy()
# plane[3] *= scale
ret_dict = {
"object_code": object_code,
"obj_pc": object_pc,
"plane": plane,
"scale": scale,
}
return ret_dict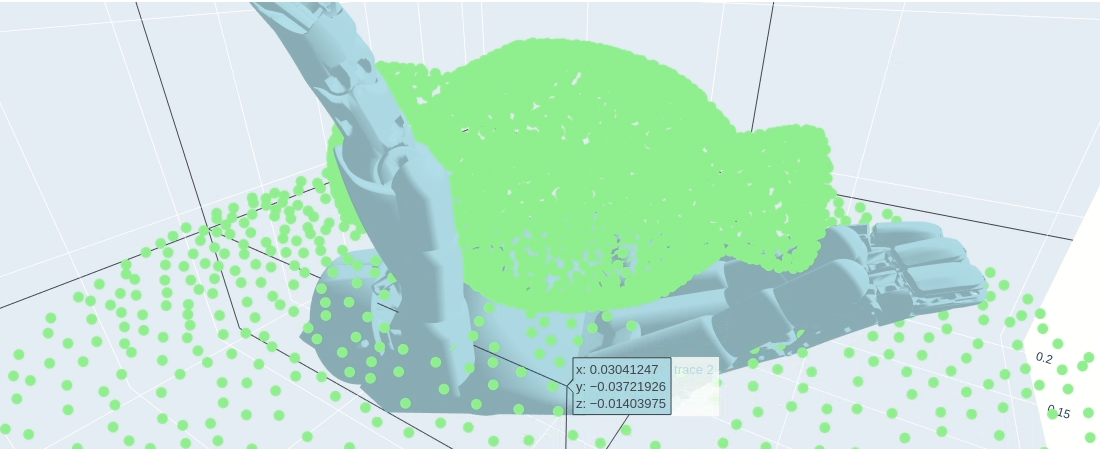
3.教师PPO策略的训练
pytorch安装
bash
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2+cu118 \
-f https://download.pytorch.org/whl/torch_stable.html
# 验证
python -c "import torch; print(torch.__version__, torch.version.cuda)"
# 应输出: 2.0.1+cu118 11.8修改setup.py
python
"""Installation script for the 'isaacgymenvs' python package."""
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
from setuptools import setup, find_packages
import os
root_dir = os.path.dirname(os.path.realpath(__file__))
INSTALL_REQUIRES = [
"gym==0.21.0",
"torch==2.0.1", # RTX 4090 适配:cu118
"torchvision==0.15.2",
"torchaudio==2.0.2",
"matplotlib==3.5.3",
"numpy==1.23.5",
"tensorboard==2.13.0",
"tqdm",
"ipdb",
"pytorch-lightning==1.9.5", # 兼容 Python 3.8,若后续报错可升级到 2.0.0
"opencv-python",
"transforms3d",
"addict",
"yapf",
"h5py",
"sorcery",
"psutil",
"pynvml",
]
setup(
name="dexgrasp",
author="test",
version="0.1",
description="Benchmark environments for Dexterous Grasping in NVIDIA IsaacGym.",
keywords=["robotics", "rl"],
include_package_data=True,
python_requires=">=3.6,<3.9",
install_requires=INSTALL_REQUIRES,
packages=find_packages("."),
classifiers=["Natural Language :: English", "Programming Language :: Python :: 3.8"],
zip_safe=False,
)需要降级
matlab
pip install "setuptools<60" "wheel<0.40" "pip<24.1"
pip install -e .编译PointNet++
bash
# 切换到合适的位置(比如 gpufree-data 目录)
cd ~/gpufree-data
# 克隆仓库(用 HTTPS 避免 SSH 配置问题)
git clone https://github.com/erikwijmans/Pointnet2_PyTorch.git
# 编译pointnet++
cd ~/gpufree-data/Pointnet2_PyTorch/pointnet2_ops_lib
python setup.py install纹理缺失修复
bash
find /root/gpufree-data -name "texture_stone_stone_texture_0.jpg"
# 查找纹理实际位置
# 一般在/.../isaacgym/assets/textures/路径下
# 在Vscode中,搜索texture_stone_stone_texture_0.jpg,查找到的结果中的路径替换为上条find指令的输出结果缺少args参数
bash
# dexgrasp_policy_l20hand/dexgrasp/tasks/shadow_hand_random_load_vision.py
# 29 def __init__(self, cfg, sim_params, args, physics_engine, device_type, device_id, headless,
# 补充args参数
二、unidexgrasp理论讲解,理解数据流
2.1 基础铺垫
在深入理解 UniDexGrasp 框架之前,我们需要先掌握一些关键的基础概念和技术。这些技术构成了 UniDexGrasp 的理论基石,理解它们对于把握整个算法的设计思想至关重要。
2.1.1 SO(3)/SO(2) 旋转群与李群
定义:SO(3) 特殊正交群
SO(3)(Special Orthogonal Group in 3D)是所有三维空间中保持长度和角度不变的旋转矩阵的集合,定义为:
$$SO(3) = { R \in \mathbb{R}^{3 \times 3} \mid R^T R = I, \det(R) = 1 } \tag{2-1}$$
SO(3) 是一个李群(Lie Group),具有特殊的拓扑结构——它是一个三维流形,但不是简单连通的。这意味着在 SO(3) 上进行概率建模和优化需要特别小心。
定义:SO(2) 平面旋转群
SO(2) 是二维平面上的旋转群,可以表示为:
$$SO(2) = \left{ \begin{pmatrix} \cos\theta & -\sin\theta \ \sin\theta & \cos\theta \end{pmatrix} \mid \theta \in [0, 2\pi) \right} \tag{2-2}$$
SO(2) 等变性是 UniDexGrasp 中的一个关键概念。在抓取任务中,当整个场景和抓取目标绕重力轴(z轴)旋转相同角度 $$\phi$$ 时,策略生成的抓取轨迹也应该以相同方式旋转。这种性质称为 SO(2) 等变性,数学表示为:
$$\pi(R_z(\phi) \cdot s) = R_z(\phi) \cdot \pi(s) \tag{2-3}$$
其中 $$R_z(\phi)$$ 表示绕 z 轴旋转角度 $$\phi$$ 的变换矩阵,$$s$$ 是状态,$$\pi$$ 是策略函数。
UniDexGrasp 利用状态规范化(State Canonicalization)来实现 SO(2) 等变性。通过定义一个静态参考坐标系,将世界坐标系中的状态转换到该参考系中,使得系统对旋转角度 $$\phi$$ 具有等变性,从而提高策略学习的样本效率。
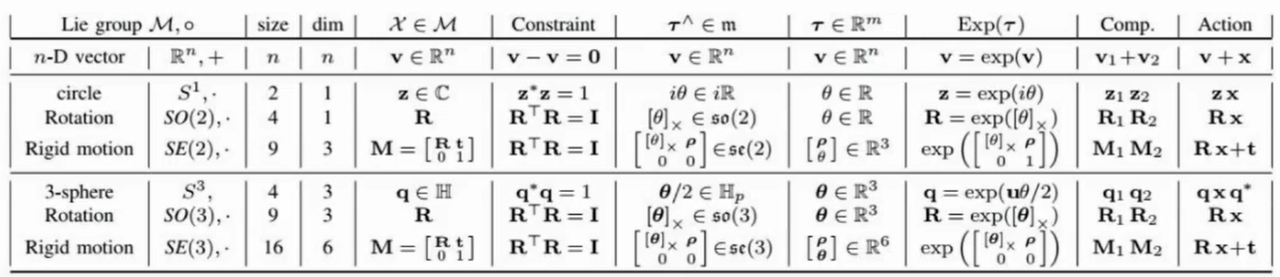
常见李群对比图
2.1.2 CVAE (条件变分自编码器)
定义:条件变分自编码器 (CVAE)
CVAE 是在标准 VAE 基础上引入条件信息的生成模型,通过编码器将输入映射到条件化的潜在分布,再通过解码器生成数据。
CVAE 的核心思想是学习条件分布 $$p(x|c)$$,其中 $$c$$ 是条件变量。其损失函数由重构损失和 KL 散度两部分组成:
$$\mathcal{L}{CVAE} = \mathbb{E}{q_\phi(z|x,c)}[\log p_\theta(x|z,c)] - D_{KL}(q_\phi(z|x,c) | p(z|c)) \tag{2-4}$$
其中:
- $$q_\phi(z|x,c) 是编码器推断的后验分布
- $$p_\theta(x|z,c) 是解码器的生成分布
- $$p(z|c) 是先验分布(通常为标准高斯)
重参数化技巧使得随机采样过程可微分:
$$z = \mu + \sigma \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \tag{2-5}$$
在 UniDexGrasp 的相关工作中,GraspTTA 使用 CVAE 来联合建模手部旋转、平移和关节角度。然而,论文指出 CVAE 存在严重的模态崩溃(Mode Collapse)问题,即无论潜在变量 $$z$$ 如何变化,生成的抓取姿态都收敛到单一模式,这限制了生成抓取的多样性。
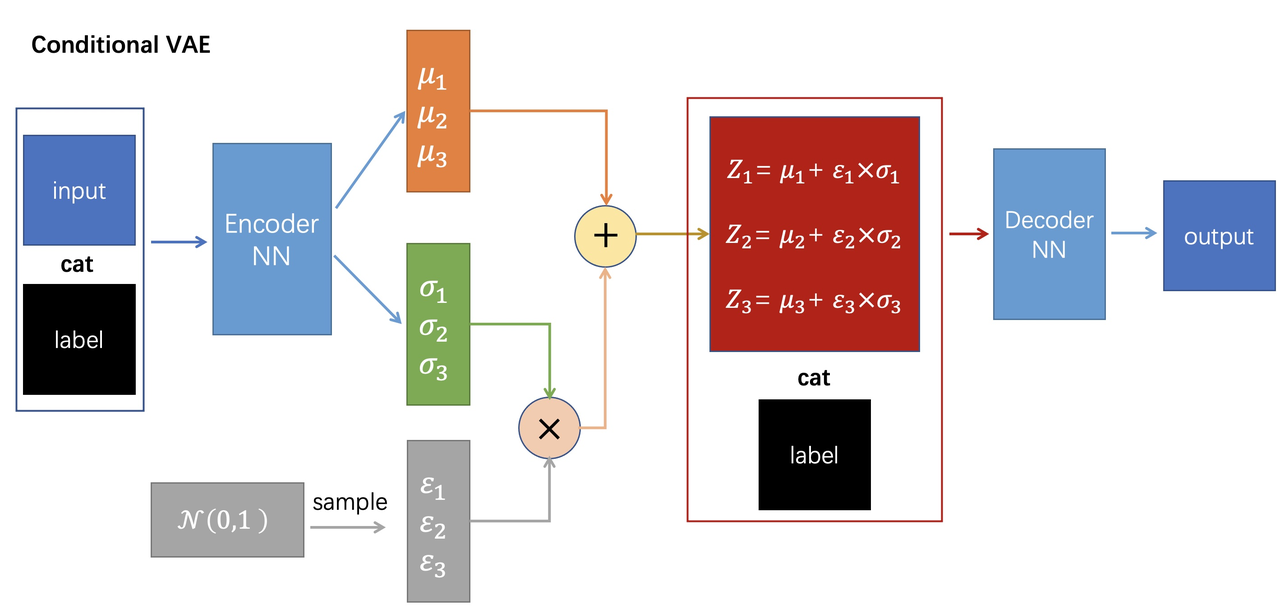
条件变分自编码器 (CVAE) 架构示意图
2.1.3 ImplicitPDF
定义:ImplicitPDF (隐式概率密度函数)
ImplicitPDF 是一种用于在旋转流形 SO(3) 上进行概率分布建模的非参数方法,由 Murphy 等人于 2021 年提出。
传统的标准化流(Normalizing Flow)在处理 SO(3) 空间时面临挑战,因为 SO(3) 具有特殊的拓扑结构(非简单连通)。ImplicitPDF 通过神经网络直接输出未归一化的对数概率密度,然后通过离散化进行归一化:
$$p(R|X) = \frac{\exp(f(X, R))}{\int_{SO(3)} \exp(f(X, R')) dR'} \tag{2-6}$$
在实际实现中,归一化通过在 SO(3) 上均匀采样或网格化来完成:
$$p(R|X) \approx \frac{\exp(f(X, R))}{\sum_{i=1}^{M} \exp(f(X, R_i)) \cdot V_i} \tag{2-7}$$
其中 $$M$$ 是采样点数量,$$V_i$$ 是每个分割区域的体积。
训练目标是最大化对数似然:
$$\mathcal{L}{NLL} = -\log p(R|X) \tag{2-8}$$
UniDexGrasp 中的 GraspIPDF 模块正是基于 ImplicitPDF 构建的,用于生成抓取姿态的旋转部分。由于 ImplicitPDF 对拓扑结构不敏感,它比传统的标准化流更适合建模 SO(3) 上的分布。
2.1.4 Glow (标准化流)
定义:Glow
Glow 是由 Kingma 和 Dhariwal 于 2018 年提出的可逆生成模型,属于标准化流(Normalizing Flow)家族,能够学习高维数据的可逆变换。
标准化流的核心思想是通过一系列可逆变换 $$f_1, f_2, ..., f_K$$ 将简单的基分布(如标准高斯)转换为复杂的 target 分布:
$$z \sim p_Z(z), \quad x = f_K \circ f_{K-1} \circ \cdots \circ f_1(z) \tag{2-9}$$
根据变量变换公式,target 分布的概率密度为:
$$p_X(x) = p_Z(f^{-1}(x)) \cdot \left| \det \frac{\partial f^{-1}(x)}{\partial x} \right| \tag{2-10}$$
Glow 引入了三种关键操作:
ActNorm:可学习的仿射变换,替代批归一化
可逆 1×1 卷积:通道间的可逆混合
仿射耦合层:保持可逆性的非线性变换
训练目标是最小化负对数似然(NLL):
$$\mathcal{L}{NLL} = -\log p_X(x) = -\log p_Z(z) - \sum^{K} \log \left| \det \frac{\partial f_k}{\partial z_k} \right| \tag{2-11}$$
UniDexGrasp 中的 GraspGlow 模块使用 Glow 来建模平移和关节角度的条件分布 $$p(t, q|X, R)$$。与 CVAE 相比,Glow 能够生成更多样化的抓取姿态,因为它使用 NLL 作为损失函数,表达能力更强。
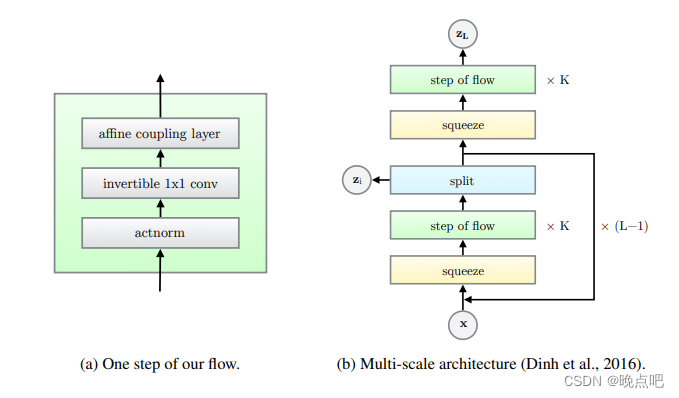
Glow 标准化流架构示意图
2.1.5 ContactNet
定义:ContactNet
ContactNet 是一种用于预测手部与物体接触模式的神经网络,最初由 GraspTTA 提出,用于抓取姿态优化。
ContactNet 的输入包括:
规范化后的物体点云 $$\tilde{X}_0$$
从手部姿态采样得到的点云 $$\tilde{X}_H$$
输出是每个物体点的接触热度(contact heat)$$c_i \in [0, 1]$$,表示该点与手部接触的概率。
接触热度的真值基于点到手部的距离计算:
$$c_i = f(D(\tilde{X}_0^{(i)}, \tilde{X}_H)) = 2^{-2 \cdot \text{sigmoid}(\beta D(\tilde{X}_0^{(i)}, \tilde{X}_H))} \tag{2-12}$$
其中 $$D(\tilde{X}_0^{(i)}, \tilde{X}_H) = \min_j |p_i - p_j|_2$$ 是物体点 $$p_i$$ 到手部点云的最小距离,$$\beta$$ 是调节系数。
在 UniDexGrasp 中,ContactNet 用于两个目的:
端到端训练:与 GraspGlow 联合训练,提供接触一致性约束
测试时优化(TTA):在推理阶段优化抓取姿态,使其符合预测的接触模式
2.1.6 PointNet++
定义:PointNet++
PointNet++ 是 Qi 等人于 2017 年提出的层次化点云特征学习网络,通过局部特征聚合捕获点云的多尺度几何信息。
PointNet++ 相比原始 PointNet 的主要改进是引入了层次化特征学习:
采样层(Sampling):使用 Farthest Point Sampling (FPS) 选择代表性点集
分组层(Grouping):在每个采样点周围构建局部邻域
- PointNet 层:对每个局部区域提取特征
这种层次结构可以形式化表示为:
$$\mathcal{F}^{(l+1)}(p) = \text{PointNet}\left( { \mathcal{F}^{(l)}(q) \mid q \in \mathcal{N}(p) } \right) \tag{2-13}$$
其中 $$\mathcal{N}(p)$$ 是点 $$p$$ 的局部邻域,$$\mathcal{F}^{(l)}$$ 是第 $$l$$ 层的特征。
在 UniDexGrasp 中,PointNet++ 被用作 GraspIPDF 的骨干网络,用于从物体点云提取几何特征。其强大的特征提取能力使得模型能够:
捕获物体的局部几何细节
理解物体的整体结构
泛化到未见过的物体类别
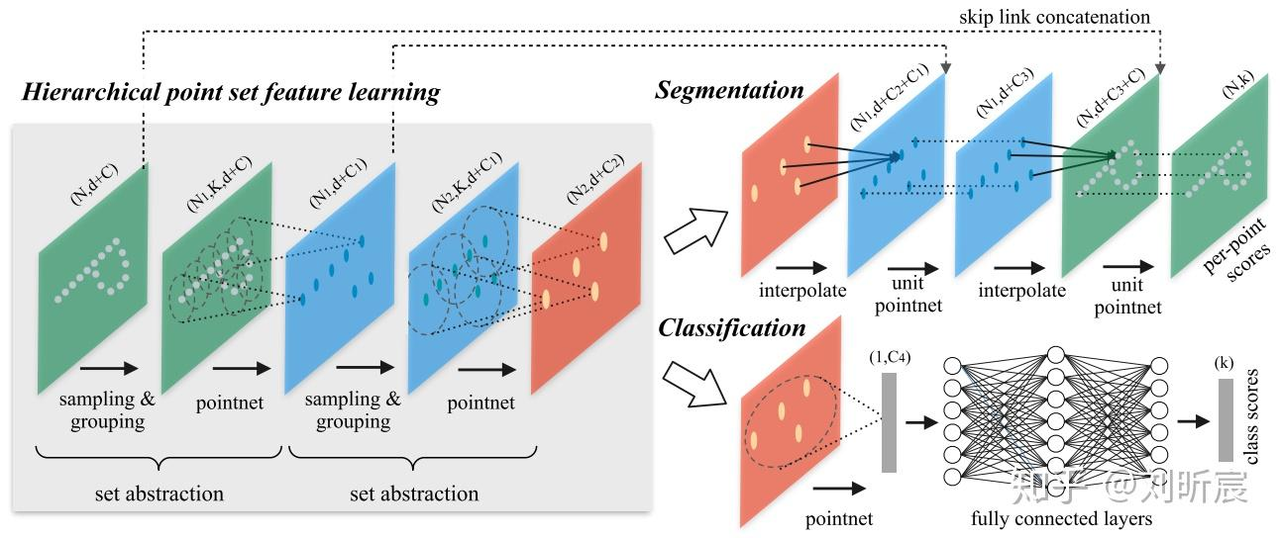
PointNet++ 层次化点云特征学习架构
2.1.7 CSDF (连续符号距离函数)
定义:CSDF (Continuous Signed Distance Function)
CSDF 是连续符号距离函数,用于隐式表示三维形状,定义为空间中任意点到物体表面的有符号距离。
对于点 $$x \in \mathbb{R}^3$$,CSDF 定义为:
$$\text{CSDF}(x) = \begin{cases} -d(x, \partial \mathcal{O}) & \text{if } x \in \mathcal{O} \ 0 & \text{if } x \in \partial \mathcal{O} \ +d(x, \partial \mathcal{O}) & \text{if } x \notin \mathcal{O} \end{cases} \tag{2-14}$$
其中 $$\mathcal{O}$$ 是物体占据的空间,$$\partial \mathcal{O}$$ 是物体表面,$$d(x, \partial \mathcal{O})$$ 是点 $$x$$ 到表面的最短距离。
CSDF 在抓取任务中的应用包括:
穿透检测:负值表示点在物体内部
接触计算:接近零的值表示接近表面
能量函数:用于优化抓取姿态的物理合理性
UniDexGrasp 在数据生成阶段使用 CSDF 相关的能量函数来优化抓取姿态,确保手部与物体之间的合理接触。
2.1.8 GraspTTA
定义:GraspTTA
GraspTTA (Test-Time Adaptation for Grasping) 是 Jiang 等人于 2021 年提出的两阶段灵巧抓取生成方法。
GraspTTA 的框架包含两个主要组件:
CVAE 生成器:以物体点云为条件,采样潜在向量并解码手部姿态
输入:物体点云特征
输出:手部旋转、平移和关节参数
ContactNet:预测手部与物体的接触模式
输入:物体点云和手部点云
输出:目标接触图
测试时优化(TTA)过程:
$$g^* = \arg\min_g |C_{pred}(g) - C_{target}|^2 \tag{2-16}$$
其中 $$C_{pred}$$ 是当前抓取姿态的接触图,$$C_{target}$$ 是 ContactNet 预测的目标接触图。
UniDexGrasp 与 GraspTTA 的主要区别:
| 特性 | GraspTTA | UniDexGrasp |
|---|---|---|
| 旋转建模 | CVAE 联合建模 | GraspIPDF 单独建模 SO(3) |
| 多样性 | 存在模态崩溃 | Glow 生成多样化抓取 |
| 执行策略 | 无 | 目标条件 RL 策略 |
| 泛化能力 | 有限 | 跨类别通用泛化 |
2.1.9 CLIP
定义:CLIP (Contrastive Language-Image Pre-training)
CLIP 是 OpenAI 于 2021 年提出的视觉-语言预训练模型,通过对比学习在大规模图像-文本对上学习联合表示。
CLIP 的核心架构包含两个编码器:
图像编码器:Vision Transformer (ViT) 或 ResNet
文本编码器:Transformer-based 语言模型
对比学习目标:最大化匹配图像-文本对的相似度,最小化不匹配对的相似度。
$$\mathcal{L}{CLIP} = -\frac{1}{N} \sum^{N} \left( \log \frac{\exp(\langle I_i, T_i \rangle / \tau)}{\sum_{j=1}^{N} \exp(\langle I_i, T_j \rangle / \tau)} + \log \frac{\exp(\langle I_i, T_i \rangle / \tau)}{\sum_{j=1}^{N} \exp(\langle I_j, T_i \rangle / \tau)} \right) \tag{2-17}$$
其中 $$\langle I, T \rangle$$ 是图像和文本嵌入的余弦相似度,$$\tau$$ 是温度参数。
在 UniDexGrasp 中,CLIP 被用于语言引导的抓取选择:
生成多个抓取候选
渲染每个抓取姿态的图像
使用 CLIP 计算图像与语言指令的相似度
选择相似度最高的抓取作为目标
这使得机器人能够根据人类指令(如"握住锤子的手柄")执行功能性的抓取操作。
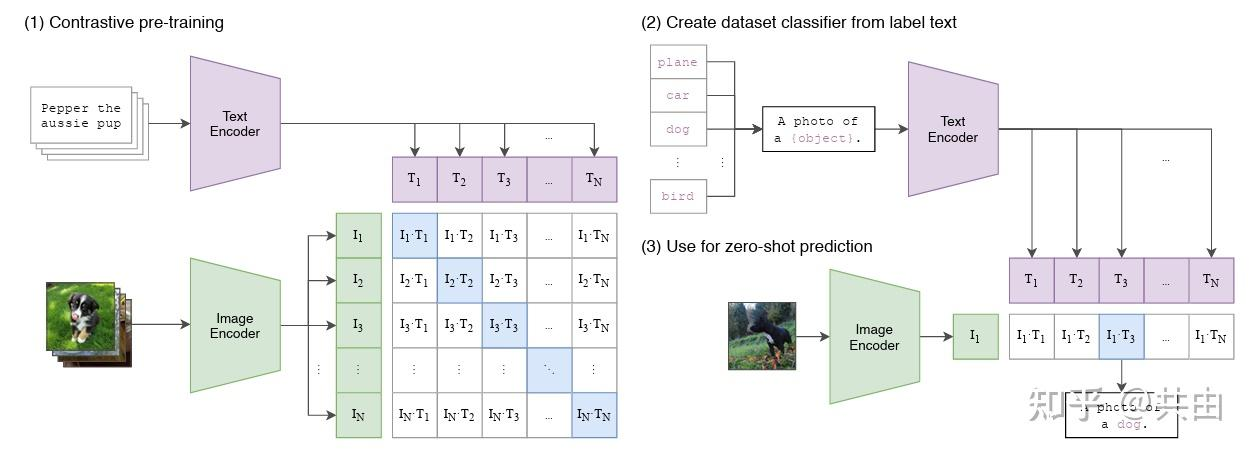
CLIP原理图
2.2 理解框架与数据流
2.2.1 两阶段架构概述
UniDexGrasp 将灵巧抓取任务分解为两个主要阶段:
抓取姿态生成阶段(Grasp Proposal Generation)
输入:物体点云 $$X_0 \in \mathbb{R}^{N \times 3}$$
输出:多样化的抓取姿态候选 $$g = (R, t, q)$$
目标条件抓取执行阶段(Goal-Conditioned Grasp Execution)
输入:目标抓取姿态 $$g$$、场景点云 $$X_t$$、机器人本体感知 $$s_r$$
输出:控制动作 $$a_t$$
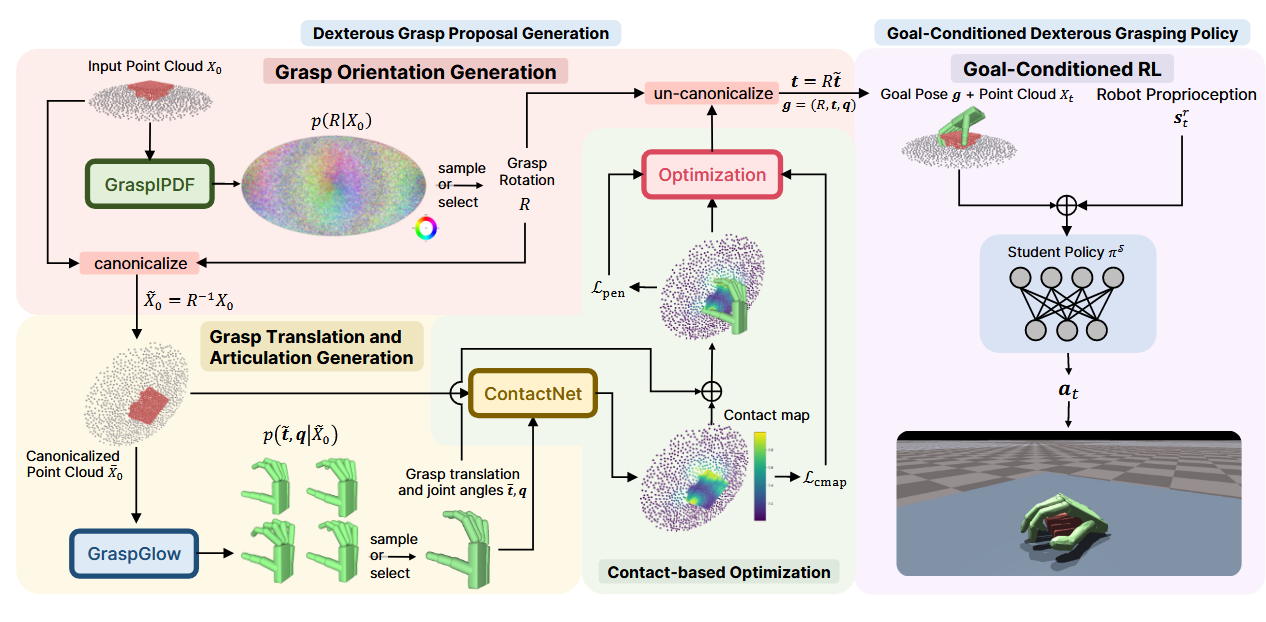
UniDexGrasp框架总览
2.2.2 抓取姿态生成阶段
抓取姿态生成阶段采用三阶段分解策略,将联合分布 $$p(g|X_0)$$ 分解为:
$$p(g|X_0) = p(R|X_0) \cdot p(t, q|X_0, R) \tag{2-18}$$
步骤 1:GraspIPDF - 旋转生成
GraspIPDF 基于 ImplicitPDF 建模条件分布 $$p(R|X_0)$$:
$$p(R|X_0) = \frac{\exp(f(X_0, R))}{\sum_{i=1}^{M} \exp(f(X_0, R_i)) \cdot V_i} \tag{2-19}$$
数据流:
PointNet++ 提取物体点云特征
神经网络 $$f$$ 输出未归一化的对数概率
在 SO(3) 的离散网格上归一化
根据概率采样旋转 $$R$$
步骤 2:GraspGlow - 平移与关节角度生成
给定旋转 $$R$$ 后,首先对点云进行规范化:
$$\tilde{X}_0 = R^{-1} X_0 \tag{2-20}$$
这使得任务从"预测给定旋转 $$R$$ 的抓取"简化为"预测旋转为单位矩阵 $$I$$ 的抓取"。
GraspGlow 使用 Glow 建模条件分布 $$p(\tilde{t}, q|\tilde{X}_0)$$:
$$\mathcal{L}{NLL} = -\log p(\tilde{t}, q_{gt}|\tilde{X}_0) \tag{2-21}$$
数据流:
PointNet 提取规范化点云特征
Glow 从基分布采样并通过可逆变换生成 $$(\tilde{t}, q)$$
- 反规范化得到实际平移:$$t = R\tilde{t}$$
步骤 3:ContactNet - 接触优化
ContactNet 提供接触一致性约束,用于端到端训练和测试时优化。
端到端训练损失:
$$\mathcal{L}{joint} = \mathcal{L} + \mathcal{L}_{add} \tag{2-22}$$
其中附加损失 $$\mathcal{L}_{add}$$ 包含:
$$\mathcal{L}_{cmap}:当前接触图与目标接触图的 MSE
$$\mathcal{L}_{pen}:物体到手部的穿透深度
$$\mathcal{L}_{tpen}:手部关键点穿透桌面深度
$$\mathcal{L}_{spen}:手部自穿透惩罚
测试时优化(TTA):
$$E_{TTA} = \lambda_{cmap}E_{cmap} + \lambda_{pen}E_{pen} + \lambda_{tpen}E_{tpen} + \lambda_{spen}E_{spen} \tag{2-23}$$
通过 300 步优化,使抓取姿态更符合预测的接触模式。
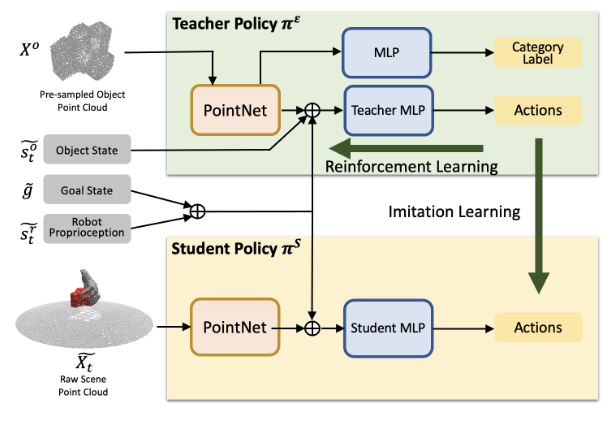
2.2.3 目标条件抓取执行阶段
抓取执行阶段采用目标条件的强化学习策略,学习从视觉观测到控制动作的映射。
状态空间定义
教师策略状态(可访问 oracle 信息):
$$S_t^E = (s_r^t, s_o^t, X^O, g) \tag{2-24}$$
学生策略状态(仅视觉观测):
$$S_t^S = (s_r^t, \tilde{X}_t, g) \tag{2-25}$$
状态规范化实现 SO(2) 等变性
定义静态参考坐标系,原点位于初始手部位置 $$(0, 0, h_0)$$,参考系的欧拉角为 $$(0, 0, \phi)$$。
状态转换公式:
$$\tilde{S}_t^E = (\tilde{s}_r^t, \tilde{s}_o^t, X^O, \tilde{g}) \tag{2-26}$$
这使得初始手部在参考系中的姿态固定为 $$(\frac{\pi}{2}, 0, 0)$$,系统对绕 z 轴的旋转具有等变性。
目标条件奖励函数
$$r = r_{goal} + r_{reach} + r_{lift} + r_{move} \tag{2-27}$$
$$r_{goal}:当前手部配置与目标配置的距离惩罚
$$r_{reach}:鼓励手指接触物体
$$r_{lift}:鼓励抬起物体(仅在达到目标姿态时非零)
$$r_{move}:鼓励物体移动到目标位置
教师-学生蒸馏
教师策略使用 PPO 算法训练,学生策略通过 DAgger 模仿学习从教师策略蒸馏:
$$\pi^S = \arg\min_{\pi^S} |\pi^E(S^E) - \pi^S(S^S)|_2^2 \tag{2-28}$$
物体课程学习
三阶段课程学习策略:
阶段 1:在单个物体上训练
阶段 2:在单个类别内的多个物体上训练
- 阶段 3:在所有类别的物体上训练
2.3 实验结果分析
2.3.1 数据集与评价指标
数据集统计
UniDexGrasp 使用 DexGraspNet 数据集进行训练,包含:
| 统计项 | 数值 |
|---|---|
| 物体实例总数 | 5,519 |
| 物体类别数 | 133 |
| 有效抓取姿态数 | 112 万+ |
| 训练实例 | 3,251 |
| 已见类别未见实例 | 754 |
| 未见类别实例 | 1,514 |
评价指标
抓取姿态生成指标:
$$Q_1$$:使抓取不稳定所需的最小扰动力矩
obj. pen.:物体到手部的最大穿透深度(cm)
$$\sigma_R^2$$:旋转方差,衡量旋转多样性
$$\sigma_{T|R}^2$$:固定旋转下的平移方差
$$\sigma_{\theta|R}^2$$:固定旋转下的关节角度方差
抓取执行指标:
成功率:物体被成功抓取并抬起的比例
穿透深度:执行过程中的穿透程度
2.3.2 抓取姿态生成实验
与基线方法的对比结果:
| 方法 | 已见类别 Q_1 ↑ | 已见类别 pen. ↓ | 未见类别 Q_1 ↑ | 未见类别 pen. ↓ | \sigma_R (degree) |
|---|---|---|---|---|---|
| GraspTTA (C+T) | 0.0269 | 0.354 | 0.0239 | 0.363 | 4.9 |
| DDG | 0.0357 | 0.319 | 0.0223 | 0.338 | 0.0 |
| R+C+T | 0.0362 | 0.251 | 0.0336 | 0.235 | 128.0 |
| ReLie+T | 0.0190 | 0.219 | 0.0191 | 0.225 | 109.9 |
| ProHMR+T | 0.0210 | 0.202 | 0.0221 | 0.192 | 88.4 |
| Ours (R+GL+T) | 0.0423 | 0.205 | 0.0322 | 0.220 | 127.6 |
关键发现:
UniDexGrasp 在 $$Q_1$$ 指标上显著优于所有基线,说明生成的抓取质量更高
旋转方差 $$\sigma_R$$ 达到 127.6°,说明生成的抓取具有高度多样性
- 穿透深度较低,表明生成的抓取物理合理性更好
2.3.3 抓取执行实验
状态基策略的实验结果:
| 方法 | 训练集 | 已见类别未见实例 | 未见类别 |
|---|---|---|---|
| MP (运动规划) | 0.12±0.01 | 0.02±0.00 | 0.02±0.01 |
| PPO (RL 基线) | 0.14±0.06 | 0.11±0.04 | 0.09±0.06 |
| DAPG (IL 基线) | 0.13±0.05 | 0.13±0.08 | 0.11±0.05 |
| ILAD | 0.25±0.03 | 0.22±0.04 | 0.20±0.05 |
| Ours | 0.74±0.07 | 0.71±0.05 | 0.66±0.06 |
视觉基策略的实验结果:
| 测试条件 | 训练集 | 已见类别 | 未见类别 |
|---|---|---|---|
| GT 目标 | 0.68±0.06 | 0.65±0.05 | 0.63±0.04 |
| 预测目标 (a) 小穿透 | 0.66±0.04 | 0.59±0.04 | 0.58±0.05 |
| 预测目标 (b) 大穿透 | 0.63±0.05 | 0.54±0.05 | 0.57±0.04 |
| 预测目标 (c) 无接触 | 0.47±0.04 | 0.37±0.05 | 0.39±0.04 |
关键发现:
教师策略在训练集上达到 74% 的成功率,显著优于所有基线
学生策略(视觉基)成功率下降约 6-7%,但仍保持较高水平
策略对目标姿态的小扰动具有鲁棒性
首次实现了跨类别通用灵巧抓取,未见类别成功率达 66%
2.3.4 消融实验分析
旋转解耦的有效性
| 配置 | 已见类别 Q_1 ↑ | 已见类别 pen. ↓ | 未见类别 Q_1 ↑ | 未见类别 pen. ↓ |
|---|---|---|---|---|
| 不解耦 (ReLie+T) | 0.0190 | 0.219 | 0.0191 | 0.225 |
| 不解耦 (ProHMR+T) | 0.0210 | 0.202 | 0.0221 | 0.192 |
| 解耦旋转 (Ours) | 0.0423 | 0.205 | 0.0322 | 0.220 |
实验表明,将旋转从平移和关节角度中解耦出来,使用专门的模型(IPDF)建模 SO(3) 分布,能够显著提升抓取质量。
测试时优化 (TTA) 的有效性
| 配置 | Q_1 ↑ | pen. ↓ |
|---|---|---|
| 无 TTA | 0.0013 | 0.744 |
| 有 TTA | 0.0423 | 0.205 |
TTA 显著提升了抓取质量,降低了穿透深度。
状态规范化的有效性
| 配置 | 训练集 | 已见类别 | 未见类别 |
|---|---|---|---|
| 无状态规范化 | 0.59±0.06 | 0.54±0.07 | 0.51±0.04 |
| 有状态规范化 | 0.74±0.07 | 0.71±0.05 | 0.66±0.06 |
状态规范化带来的 SO(2) 等变性显著提升了策略学习的效果。
物体课程学习的有效性
| 配置 | 训练集 | 已见类别 | 未见类别 |
|---|---|---|---|
| 无课程学习 | 0.31±0.07 | 0.23±0.06 | 0.21±0.04 |
| 1 阶段课程 | 0.58±0.07 | 0.55±0.03 | 0.55±0.05 |
| 2 阶段课程 | 0.68±0.06 | 0.67±0.07 | 0.62±0.05 |
| 3 阶段课程 | 0.74±0.07 | 0.71±0.05 | 0.66±0.06 |
三阶段课程学习(单物体 → 单类别 → 全类别)显著提升了跨类别泛化能力。
语言引导抓取实验
UniDexGrasp 结合 CLIP 实现了语言引导的抓取选择。实验表明:
在"握住瓶子瓶颈/瓶身"任务上达到约 90% 的准确率
在"握住锤子手柄/锤头"任务上达到约 90% 的准确率
仅需 10 分钟的微调即可实现
这验证了 UniDexGrasp 生成多样化抓取姿态的能力,以及结合视觉-语言模型实现功能性抓取的潜力。
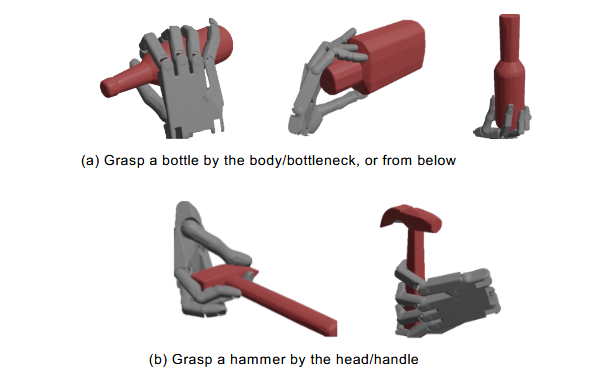
语言引导抓取实验结果
三、抓取提案生成的参数解读与训练监控
3.1 核心流程
plain text
物体点云 → GraspIPDF(旋转预测) → GraspGlow(姿态预测) → ContactNet(TTA优化) → 姿态映射 → L20抓取姿态| 网络 | 功能 | 配置文件 |
|---|---|---|
| GraspIPDF | 预测手掌相对于物体的旋转 | ipdf_config.yaml |
| GraspGlow | 预测手掌平移和关节角度 | glow_config.yaml / glow_joint_config.yaml |
| ContactNet | 预测接触图,用于测试时适应(TTA)优化 | cm_net_config.yaml |
3.2 数据准备
1. 创建数据目录
bash
mkdir -p data2. 下载数据集
从 PKU 镜像站 下载以下数据:
mjcf/: ShadowHand 的 MJCF 模型文件
DFCData/: 抓取标注数据
datasetv4.1/: 数据集划分meshdatav3/: 物体网格和点云splits/: 训练/测试划分文件
3. 数据目录结构
plain text
dexgrasp_generation/
├── data/
│ ├── DFCData/
│ │ ├── datasetv4.1/ # 数据集标注
│ │ ├── meshdatav3/ # 物体网格和点云
│ │ └── splits/ # 数据划分
│ └── mjcf/
│ ├── shadow_hand.xml # ShadowHand 模型
│ ├── meshes/ # 手网格文件
│ └── textures/ # 纹理文件
├── mini_generation/ # 小规模测试数据
│ └── DFCData/4. 使用小规模测试数据
项目已包含 mini_generation/ 目录,可用于快速测试,无需下载完整数据集。
3.3 模型训练
1. 总体流程
抓取生成网络包含三个子网络,训练分为独立训练和联合训练两个阶段:
plain text
阶段一:独立训练(无依赖,可并行)
├── 1. GraspIPDF (旋转预测)
├── 2. ContactNet (接触图预测)
└── 3. GraspGlow (基础姿态预测)
阶段二:联合训练(依赖阶段一的权重)
└── 4. GraspGlow Joint (联合微调)2. 详细训练顺序
阶段一:独立训练
| 顺序 | 网络 | 训练内容 | 依赖 | 输出 |
|---|---|---|---|---|
| 1 | GraspIPDF | 预测手掌旋转矩阵 | 无 | 旋转候选 |
| 2 | ContactNet | 预测手-物体接触图 | 无 | 接触图 |
| 3 | GraspGlow | 预测平移和关节角度 | 无 | 抓取姿态 |
注意:阶段一的三个网络相互独立,可以按任意顺序训练,也可以并行训练。
阶段二:联合训练
| 顺序 | 网络 | 训练内容 | 依赖 | 说明 |
|---|---|---|---|---|
| 4 | GraspGlow Joint | 联合优化旋转+平移+接触 | IPDF权重+CMNet权重 | 加载预训练权重联合微调 |
关键区别:
glow_config→ 基础训练(joint_training: False)glow_joint_config→ 联合训练(joint_training: True,加载 IPDF 和 CMNet)
3. 为什么 Glow Joint 要最后训练?
从 glow_joint.yaml 配置可以看出:
yaml
joint_training: True
rotation_net:
type: ipdf
ckpt_path: exp/temp_ipdf_train/ckpt/model_000001.pt # 依赖 IPDF
contact_net:
type: cm_net
ckpt_path: exp/temp_cmap_train/ckpt/model_000001.pt # 依赖 CMNet联合训练时会:
加载预训练的 IPDF 作为
rotation_net加载预训练的 CMNet 作为
contact_net
- 同时优化流模型 + 旋转网络 + 接触图网络的损失
4. 快速训练命令
bash
# 1. 训练 GraspIPDF(旋转预测)
python ./network/train.py \
--config-name ipdf_config \
--exp-dir ./myrun/exp_ipdf
# 2. 训练 ContactNet(接触图预测)
python ./network/train.py \
--config-name cm_net_config \
--exp-dir ./myrun/exp_cm
# 3. 训练 GraspGlow 基础(姿态预测)
python ./network/train.py \
--config-name glow_config \
--exp-dir ./myrun/exp_glowbash
# 4. 联合训练(需先完成 1 和 2)
python ./network/train.py \
--config-name glow_joint_config \
--exp-dir ./myrun/exp_glow_joint注意:glow_joint_config 会自动加载 IPDF 和 CMNet 的预训练权重,需确保路径正确。
5. 配置参数速查
GraspIPDF (configs/ipdf_config.yaml)
| 参数 | 默认值 | 说明 |
|---|---|---|
learning_rate | 0.001 | 学习率 |
batch_size | 16 | 批次大小 |
total_epoch | 250 | 总训练轮数 |
num_train_queries | 4096 | 查询点数量 |
ContactNet (configs/cm_net_config.yaml)
| 参数 | 默认值 | 说明 |
|---|---|---|
learning_rate | 0.001 | 学习率 |
batch_size | 16 | 批次大小 |
total_epoch | 250 | 总训练轮数 |
out_channel | 10 | 接触图离散化级别 |
GraspGlow (configs/glow_config.yaml)
| 参数 | 默认值 | 说明 |
|---|---|---|
learning_rate | 0.001 | 学习率 |
batch_size | 64 | 批次大小 |
total_epoch | 250 | 总训练轮数 |
flow.layer | 21 | Glow 流层数 |
joint_training | False | 是否联合训练 |
GraspGlow Joint (configs/glow_joint_config.yaml)
| 参数 | 默认值 | 说明 |
|---|---|---|
learning_rate | 0.001 | 学习率(通常比基础训练小) |
batch_size | 8 | 批次大小(联合训练显存占用大) |
total_epoch | 2000 | 总训练轮数 |
joint_training | True | 启用联合训练 |
6. 评估时的数据流
plain text
输入: 物体点云
│
▼
┌─────────────┐
│ GraspIPDF │ ──► 生成旋转候选
└──────┬──────┘
│
▼
┌─────────────┐
│ GraspGlow │ ──► 基于旋转生成平移+关节角度
└──────┬──────┘
│
▼
┌─────────────┐
│ ContactNet │ ──► 预测接触图
└──────┬──────┘
│
▼
┌─────────────┐
│ TTA │ ──► 测试时适应优化
│ (可选) │
└─────────────┘3.4 训练监控
训练过程中会自动记录:
TensorBoard: 在
/tensorboard/目录日志文件: 在
/log.txt模型检查点: 在
/ckpt/
查看训练进度:
bash
tensorboard --logdir /path/to/your/tensorboard3.5 模型评估
1. 使用预训练模型评估
项目 runs/ 目录已包含预训练模型:
exp_ipdf/ckpt/: GraspIPDF 检查点exp_glow/ckpt/: GraspGlow 检查点exp_cm/ckpt/: ContactNet 检查点
2. 运行评估
bash
python ./network/eval.py --config-name eval_config \
--exp-dir ./eval评估配置 (configs/eval_config.yaml):
| 参数 | 默认值 | 说明 |
|---|---|---|
tta.iterations | 300 | TTA 优化迭代次数 |
tta.lr | 0.001 | TTA 学习率 |
tta.batch_size | 50 | TTA 批次大小 |
q1.thres_pen | 0.005 | 穿透阈值 |
q1.thres_tpen | 0.01 | 指尖穿透阈值 |
3. 评估输出
评估结果保存在 exp_dir/result.pt,包含:
object_code: 物体编码scale: 物体缩放比例canon_obj_pc: 规范化物体点云tta_hand_pose: 优化后的抓取姿态 (平移 + 旋转 + 关节角度)q1: 抓取质量指标
3.6 可视化与数据转换
1. 可视化抓取结果
可视化 ShadowHand 和映射后的 L20 抓取姿态:
bash
python ./tests/visualize_result_l20_shadow.py \
--exp_dir ./eval \
--num 0 \
--canonical_frame 0参数说明:
| 参数 | 说明 |
|---|---|
--exp_dir | 评估结果目录 |
--num | 显示的物体索引 |
--canonical_frame | 是否使用规范坐标系 (0/1) |
2. 转换数据用于策略训练
将评估结果转换为策略训练所需的格式:
bash
python ./tests/data_for_RL.py修改配置:
编辑 tests/data_for_RL.py 文件,修改以下路径:
python
pt_file_path = "./eval/result.pt" # 输入:评估结果文件
save_dir = "./datasetv4.1/core" # 输出:策略训练数据目录输出格式:
每个物体保存为 object_code/00000.npz,包含:
arr_0: 手部关节角度 + 腕部位姿 (字典格式)WRJRx,WRJRy,WRJRz: 手腕旋转 (欧拉角)WRJTx,WRJTy,WRJTz: 手腕平移各手指关节角度
arr_1: 物体缩放比例arr_2: 平面参数
3.7 项目结构
plain text
dexgrasp_generation/
├── configs/ # 配置文件
│ ├── ipdf_config.yaml # GraspIPDF 配置
│ ├── glow_config.yaml # GraspGlow 配置
│ ├── glow_joint_config.yaml # GraspGlow 联合训练配置
│ ├── cm_net_config.yaml # ContactNet 配置
│ ├── eval_config.yaml # 评估配置
│ ├── model/ # 模型架构配置
│ └── dataset/ # 数据集配置
├── network/ # 网络训练和评估
│ ├── train.py # 训练脚本
│ ├── eval.py # 评估脚本
│ ├── trainer.py # 训练器类
│ ├── data/ # 数据加载
│ └── models/ # 模型定义
│ ├── backbones/ # 骨干网络
│ ├── contactnet/ # ContactNet 实现
│ ├── graspglow/ # GraspGlow 实现
│ └── graspipdf/ # GraspIPDF 实现
├── datasets/ # 数据集和手部模型
│ ├── dex_dataset.py # 数据集类
│ ├── shadow_hand_builder.py # ShadowHand 构建器
│ └── l20_hand_builder.py # L20 手部构建器
├── tests/ # 测试和可视化
│ ├── visualize_result_l20_shadow.py # 可视化脚本
│ ├── data_for_RL.py # 数据转换脚本
│ └── visualize_data.py # 数据可视化
├── utils/ # 工具函数
│ ├── hand_model.py # 手部模型
│ ├── eval_utils.py # 评估工具
│ └── visualize.py # 可视化工具
├── data/ # 数据目录
├── runs/ # 训练输出
│ ├── exp_ipdf/ # GraspIPDF 训练结果
│ ├── exp_glow/ # GraspGlow 训练结果
│ └── exp_cm/ # ContactNet 训练结果
├── thirdparty/ # 第三方库
│ ├── pytorch_kinematics/ # PyTorch 运动学
│ ├── nflows/ # 标准化流
│ └── CSDF/ # CSDF 库
└── scripts/ # 数据处理脚本3.8 快速开始命令
bash
# 1. 激活环境
conda activate unidexgrasp
# 2. 训练 GraspIPDF
python ./network/train.py --config-name ipdf_config --exp-dir ./runs/exp_ipdf
# 3. 训练 GraspGlow (阶段 1)
python ./network/train.py --config-name glow_config --exp-dir ./runs/exp_glow
# 4. 训练 GraspGlow (阶段 2)
python ./network/train.py --config-name glow_joint_config --exp-dir ./runs/exp_glow
# 5. 训练 ContactNet
python ./network/train.py --config-name cm_net_config --exp-dir ./runs/exp_cm
# 6. 评估 (使用预训练模型)
python ./network/eval.py --config-name eval_config --exp-dir ./eval
# 7. 可视化
python ./tests/visualize_result_l20_shadow.py --exp_dir ./eval --num 3
# 8. 转换数据用于策略训练
python ./tests/data_for_RL.py四、教师网络PPO的参数解读,迁移到linkerhand的注意点
4.1 快速开始
1.基本训练命令
bash
python train.py \
--task=ShadowHandGrasp \
--algo=ppo \
--seed=7 \
--rl_device=cuda:0 \
--sim_device=cuda:0 \
--logdir=logs/test2.基本测试命令
bash
python train.py \
--task=ShadowHandGrasp \
--algo=ppo \
--seed=7 \
--rl_device=cuda:0 \
--sim_device=cuda:0 \
--logdir=logs/test \
--model_dir=logs/test_seed7/model_10000.pt \
--test4.2 训练模式
1. 状态输入训练 (State-based)
使用机器人状态信息(关节位置、速度等)进行训练:
bash
CUDA_VISIBLE_DEVICES=0 \
python train.py \
--task=ShadowHandGrasp \
--algo=ppo \
--seed=7 \
--rl_device=cuda:0 \
--sim_device=cuda:0 \
--logdir=logs/test2. 视觉输入训练 (Vision-based)
使用点云数据作为输入进行训练:
bash
CUDA_VISIBLE_DEVICES=0 \
python train.py \
--task=ShadowHandRandomLoadVision \
--algo=ppo \
--seed=1 \
--rl_device=cuda:0 \
--sim_device=cuda:0 \
--logdir=logs/test \
--vision \
--backbone_type=pn \
--headless支持的视觉骨干网络类型:
pn: PointNet 基础点云编码器transpn: 带实例信息的 Transformer PointNet
3. 冻结骨干网络训练
在训练策略网络时冻结视觉骨干网络:
bash
python train.py \
--task=ShadowHandRandomLoadVision \
--algo=ppo \
--vision \
--backbone_type=pn \
--freeze_backbone \
--model_dir=example_model/model.pt4.3 测试模式
1.加载模型进行测试
bash
python train.py \
--task=ShadowHandGrasp \
--algo=ppo \
--seed=7 \
--rl_device=cuda:0 \
--sim_device=cuda:0 \
--logdir=logs/test \
--model_dir=logs/test_seed7/model_10000.pt \
--test \
--headless2.关键参数说明
| 参数 | 说明 |
|---|---|
--test | 启用测试模式,只进行推理不训练 |
--model_dir | 预训练模型路径 |
--headless | 无界面模式运行 |
4.4 配置文件详解
项目使用两个主要的 YAML 配置文件:
1. 算法配置: cfg/ppo/config.yaml
yaml
seed: -1 # 随机种子,-1 表示随机生成
clip_observations: 5.0 # 观测值裁剪范围
clip_actions: 1.0 # 动作值裁剪范围
policy:
pi_hid_sizes: [1024, 1024, 512, 512] # 策略网络隐藏层大小
vf_hid_sizes: [1024, 1024, 512, 512] # 价值网络隐藏层大小
activation: elu # 激活函数类型
learn:
agent_name: shadow_hand
test: False
resume: 0
save_interval: 500 # 模型保存间隔(迭代次数)
print_log: True
# 训练参数
max_iterations: 10000 # 最大训练迭代次数
cliprange: 0.2 # PPO 裁剪参数 epsilon
ent_coef: 0 # 熵正则化系数
nsteps: 8 # 每次更新的时间步数
noptepochs: 5 # 每次数据收集后的优化轮数
nminibatches: 4 # 每次优化的 minibatch 数量
max_grad_norm: 1 # 梯度裁剪范数
optim_stepsize: 3.e-5 # 学习率
schedule: adaptive # 学习率调度策略
desired_kl: 0.016 # 目标 KL 散度(用于自适应学习率)
gamma: 0.96 # 折扣因子
lam: 0.95 # GAE 参数 lambda
init_noise_std: 0.8 # 初始动作噪声标准差
log_interval: 1 # 日志记录间隔
asymmetric: False # 是否使用非对称 Actor-Critic| 参数 | 解读 |
|---|---|
cliprange=0.2 | 标准 PPO 裁剪,限制策略更新幅度,避免策略崩溃 |
nsteps=8 | Rollout 长度较短(配合 1000 并行环境),数据新鲜度高 |
nminibatches=4 | 每次更新分成 4 个 mini-batch,总样本数 = 1000×8 = 8000 |
optim_stepsize=3e-5 | 非常低的学习率,大网络+稳定训练需要,收敛慢但稳定 |
schedule=adaptive | 根据实际 KL 散度动态调整学习率:KL 过大则 lr÷1.5,过小则 lr×1.5 |
desired_kl=0.016 | 自适应调度的目标 KL 阈值 |
gamma=0.96, lam=0.95 | GAE 参数,bias-variance 权衡,lam 接近 1 方差小但偏差大 |
ent_coef=0 | 无熵正则,依赖初始噪声 std 和 clipping 保证探索 |
init_noise_std=0.8 | 动作分布初始标准差,控制探索程度 |
2. 任务配置: cfg/shadow_hand_grasp.yaml
yaml
env:
env_name: "shadow_hand_grasp"
numEnvs: 1000 # 并行环境数量
envSpacing: 1.5 # 环境间距
episodeLength: 200 # 每回合最大步数
enableDebugVis: False # 启用调试图可视化
aggregateMode: 1 # 物理实体聚合模式
# 初始化设置
random_prior: True # 随机选择初始抓取姿态
random_time: True # 随机化时间步
repose_z: True # 重新定位物体高度
goal_cond: False # 是否使用目标条件策略
# 物体配置
object_code_dict: { # 训练使用的物体及其尺寸
'sem/Kettle-xxx': [0.08],
'core/bottle-xxx': [0.06],
# ... 更多物体
}
# 观测设置
observationType: "full_state" # 观测类型
asymmetric_observations: False # 非对称观测
# 控制参数
useRelativeControl: False
dofSpeedScale: 20.0
actionsMovingAverage: 1.0
controlFrequencyInv: 1 # 控制频率 (60 Hz)4.5 可调训练参数说明
命令行参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
--task | str | "Humanoid" | 任务类型,可选:ShadowHandGrasp, ShadowHandRandomLoadVision |
--algo | str | "happo" | 算法类型,使用 ppo |
--seed | int | None | 随机种子 |
--test | bool | False | 测试模式 |
--vision | bool | False | 启用视觉输入 |
--freeze_backbone | bool | False | 冻结视觉骨干网络 |
--backbone_type | str | "" | 视觉骨干类型:pn / transpn |
--headless | bool | False | 无界面模式 |
--rl_device | str | "cuda:0" | RL 计算设备 |
--sim_device | str | "cuda:0" | 仿真计算设备 |
--logdir | str | "logs/" | 日志保存目录 |
--model_dir | str | "" | 模型加载路径 |
--num_envs | int | 0 | 覆盖配置中的环境数量 |
--episode_length | int | 0 | 覆盖配置中的回合长度 |
--max_iterations | int | 0 | 最大训练迭代次数 |
--randomize | bool | False | 启用域随机化 |
--torch_deterministic | bool | False | 确定性训练模式 |
4.6 网络架构配置
1.策略网络 (Policy Network)
yaml
policy:
pi_hid_sizes: [1024, 1024, 512, 512] # 4层隐藏层
vf_hid_sizes: [1024, 1024, 512, 512] # 4层隐藏层
activation: elu # 激活函数可选激活函数:
elu: Exponential Linear Unit (推荐)relu: Rectified Linear Unitselu: Scaled Exponential Linear Unitcrelu: Concatenated ReLUlrelu: Leaky ReLUtanh: 双曲正切函数sigmoid: Sigmoid 函数
| 参数 | 值 | 含义 |
|---|---|---|
pi_hid_sizes | [1024, 1024, 512, 512] | 策略网络为 4 层 MLP,参数量较大,表达能力强的教师网络 |
vf_hid_sizes | [1024, 1024, 512, 512] | 值函数网络与策略网络对称结构 |
activation | elu | 使用 ELU 激活函数,训练稳定性优于 ReLU |
2.视觉骨干网络配置
PointNet 配置:
python
backbone_type: "pn"
pc_dim: 8 # 点云输入维度 (xyz + mask + 其他特征)
feature_dim: 128 # 输出特征维度TransPointNet 配置:
python
backbone_type: "transpn"
pc_dim: 6 # 点云输入维度 (xyz + rgb)
feature_dim: 128 # 输出特征维度
state_dim: 220 # 状态输入维度
use_seg: True # 使用分割掩码4.7 奖励函数参数
在任务配置文件中可调整的奖励参数:
yaml
env:
distRewardScale: 20 # 距离奖励缩放系数
rotRewardScale: 1.0 # 旋转奖励缩放系数
actionPenaltyScale: -0.0002 # 动作惩罚系数
reachGoalBonus: 250 # 达到目标的奖励
fallDistance: 0.4 # 掉落判定距离
fallPenalty: 0.0 # 掉落惩罚
successTolerance: 0.1 # 成功判定容差
transition_scale: 0.5 # 位置过渡缩放
orientation_scale: 0.1 # 方向过渡缩放4.8 仿真环境参数
1.物理参数
yaml
sim:
substeps: 2 # 每步仿真子步数
physx:
num_threads: 4 # 物理计算线程数
solver_type: 1 # 求解器类型 (0: PGS, 1: TGS)
num_position_iterations: 8 # 位置迭代次数
num_velocity_iterations: 0 # 速度迭代次数
contact_offset: 0.002 # 接触偏移
rest_offset: 0.0 # 静止偏移
bounce_threshold_velocity: 0.2 # 反弹速度阈值
max_depenetration_velocity: 1000.0 # 最大穿透恢复速度2.域随机化参数
yaml
task:
randomize: False # 是否启用域随机化
randomization_params:
frequency: 600 # 随机化频率(仿真步数)
observations:
range: [0, .002] # 观测噪声范围
actions:
range: [0., .05] # 动作噪声范围
sim_params:
gravity:
range: [0, 0.4] # 重力随机化范围
actor_params:
hand:
color: True # 随机化颜色
tendon_properties:
damping:
range: [0.3, 3.0] # 肌腱阻尼随机化
stiffness:
range: [0.75, 1.5] # 肌腱刚度随机化
dof_properties:
damping:
range: [0.3, 3.0] # 关节阻尼随机化
stiffness:
range: [0.75, 1.5] # 关节刚度随机化
rigid_body_properties:
mass:
range: [0.5, 1.5] # 质量随机化
rigid_shape_properties:
friction:
range: [0.7, 1.3] # 摩擦系数随机化4.9 可视化与监控
1.TensorBoard 日志
训练过程中会自动记录以下指标到 TensorBoard:
Loss/value_function: 价值函数损失
Loss/surrogate: 替代损失 (PPO Clip Loss)
Policy/mean_noise_std: 策略噪声标准差
Train/mean_reward: 平均回合奖励
Train/mean_episode_length: 平均回合长度
Episode/*: 各种回合级统计信息
启动 TensorBoard:
bash
tensorboard --logdir=logs/test2.控制台输出
训练过程中会实时输出:
当前迭代次数 / 总迭代次数
计算速度 (steps/s)
收集时间和学习时间
价值函数损失和替代损失
平均动作噪声标准差
平均奖励和回合长度
总时间步数和预计剩余时间 (ETA)
4.10 PPO核心代码
ActorCritic 类初始化代码详解
python
# dexgrasp/algorithms/rl/ppo/module.py
class ActorCritic(nn.Module):
def __init__(self, obs_shape, states_shape, actions_shape, initial_std, model_cfg,
asymmetric=False, use_pc=False):
super(ActorCritic, self).__init__()
self.asymmetric = asymmetric
self.use_pc = use_pc
self.backbone_type = model_cfg['backbone_type']
self.freeze_backbone = model_cfg["freeze_backbone"]
# 从配置读取网络结构
if model_cfg is None:
actor_hidden_dim = [256, 256, 256]
critic_hidden_dim = [256, 256, 256]
activation = get_activation("selu")
else:
actor_hidden_dim = model_cfg['pi_hid_sizes'] # [1024, 1024, 512, 512]
critic_hidden_dim = model_cfg['vf_hid_sizes'] # [1024, 1024, 512, 512]
activation = get_activation(model_cfg['activation']) # elu
# 关键:观测维度硬编码!
self.num_obs = 254 # 这是硬编码的值,迁移时需要修改
# 视觉输入处理
if self.use_pc:
self.num_obs = 191 + 29 # robot_state
if self.backbone_type == "pn":
self.backbone = PointNetBackbone(pc_dim=8, feature_dim=128)
elif self.backbone_type == "transpn":
self.backbone = TransPointNetBackbone(pc_dim=6, feature_dim=128)
self.num_obs += 128 # 加上点云特征维度
# 构建 Actor (策略网络)
actor_layers = []
actor_layers.append(nn.Linear(self.num_obs, actor_hidden_dim[0])) # 254 -> 1024
actor_layers.append(activation)
for l in range(len(actor_hidden_dim)):
if l == len(actor_hidden_dim) - 1:
actor_layers.append(nn.Linear(actor_hidden_dim[l], *actions_shape)) # 512 -> 27
else:
actor_layers.append(nn.Linear(actor_hidden_dim[l], actor_hidden_dim[l + 1]))
actor_layers.append(activation)
self.actor = nn.Sequential(*actor_layers)
# 构建 Critic (值函数网络)
critic_layers = []
critic_layers.append(nn.Linear(self.num_obs, critic_hidden_dim[0])) # 254 -> 1024
critic_layers.append(activation)
for l in range(len(critic_hidden_dim)):
if l == len(critic_hidden_dim) - 1:
critic_layers.append(nn.Linear(critic_hidden_dim[l], 1)) # 512 -> 1
else:
critic_layers.append(nn.Linear(critic_hidden_dim[l], critic_hidden_dim[l + 1]))
critic_layers.append(activation)
self.critic = nn.Sequential(*critic_layers)
# 动作噪声参数 (可学习)
self.log_std = nn.Parameter(np.log(initial_std) * torch.ones(*actions_shape))
# 权重初始化 (Orthogonal 初始化)
actor_weights = [np.sqrt(2)] * len(actor_hidden_dim)
actor_weights.append(0.01)
critic_weights = [np.sqrt(2)] * len(critic_hidden_dim)
critic_weights.append(1.0)
self.init_weights(self.actor, actor_weights)
self.init_weights(self.critic, critic_weights)关键代码解读:
actor_hidden_dim = model_cfg['pi_hid_sizes']从 YAML 配置读取[1024, 1024, 512, 512]self.num_obs = 254是硬编码,这是迁移到 LinkerHand 时必须修改的地方self.log_std是可学习的动作分布标准差,控制探索程度使用 Orthogonal 初始化(
gain=√2)是 RL 中的常见做法,有助于训练稳定性
PPO Update 方法核心代码
python
# dexgrasp/algorithms/rl/ppo/ppo.py
def update(self):
mean_value_loss = 0
mean_surrogate_loss = 0
# 生成 mini-batch 采样器
batch = self.storage.mini_batch_generator(self.num_mini_batches)
for epoch in range(self.num_learning_epochs): # noptepochs = 5
for indices in batch:
# 从缓冲区采样数据
obs_batch = self.storage.observations.view(-1, *self.storage.observations.size()[2:])[indices]
actions_batch = self.storage.actions.view(-1, self.storage.actions.size(-1))[indices]
returns_batch = self.storage.returns.view(-1, 1)[indices]
old_actions_log_prob_batch = self.storage.actions_log_prob.view(-1, 1)[indices]
advantages_batch = self.storage.advantages.view(-1, 1)[indices]
old_mu_batch = self.storage.mu.view(-1, self.storage.actions.size(-1))[indices]
old_sigma_batch = self.storage.sigma.view(-1, self.storage.actions.size(-1))[indices]
# 评估当前策略
actions_log_prob_batch, entropy_batch, value_batch, mu_batch, sigma_batch = \
self.actor_critic.evaluate(obs_batch, states_batch, actions_batch)
# ===== PPO 核心:自适应学习率调度 =====
if self.desired_kl != None and self.schedule == 'adaptive':
kl = torch.sum(
sigma_batch - old_sigma_batch +
(torch.square(old_sigma_batch.exp()) + torch.square(old_mu_batch - mu_batch)) /
(2.0 * torch.square(sigma_batch.exp())) - 0.5, axis=-1
)
kl_mean = torch.mean(kl)
# KL 过大则减小学习率,过小则增大学习率
if kl_mean > self.desired_kl * 2.0:
self.step_size = max(1e-5, self.step_size / 1.5)
elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0:
self.step_size = min(1e-2, self.step_size * 1.5)
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.step_size
# ===== PPO 核心:Surrogate Loss (替代损失) =====
ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch))
surrogate = -torch.squeeze(advantages_batch) * ratio
surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(
ratio, 1.0 - self.clip_param, 1.0 + self.clip_param # clip_param = 0.2
)
surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
# ===== PPO 核心:Value Function Loss =====
if self.use_clipped_value_loss:
value_clipped = target_values_batch + \
(value_batch - target_values_batch).clamp(-self.clip_param, self.clip_param)
value_losses = (value_batch - returns_batch).pow(2)
value_losses_clipped = (value_clipped - returns_batch).pow(2)
value_loss = torch.max(value_losses, value_losses_clipped).mean()
else:
value_loss = (returns_batch - value_batch).pow(2).mean()
# 总损失 = 策略损失 + 值函数损失系数 * 值函数损失 - 熵系数 * 熵
loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()
# 反向传播与梯度裁剪
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm) # max_grad_norm = 1
self.optimizer.step()
mean_value_loss += value_loss.item()
mean_surrogate_loss += surrogate_loss.item()关键代码解读:
ratio = torch.exp(...)计算新旧策略的概率比torch.clamp(ratio, 0.8, 1.2)实现 PPO-Clip,限制更新幅度(ε=0.2)torch.max(surrogate, surrogate_clipped)取裁剪前后的最大值,防止策略退化值函数也使用 clipping,稳定值函数训练
clip_grad_norm_进行梯度裁剪,防止梯度爆炸
GAE (Generalized Advantage Estimation) 计算代码
python
# dexgrasp/algorithms/rl/ppo/storage.py
def compute_returns(self, last_values, gamma, lam):
"""
使用 GAE 计算 advantages 和 returns
gamma = 0.96, lam = 0.95
"""
advantage = 0
for step in reversed(range(self.num_transitions_per_env)): # 倒序计算
if step == self.num_transitions_per_env - 1:
# 最后一步的下一状态值用 last_values
next_values = last_values
else:
next_values = self.values[step + 1]
# TD Error: δ_t = r_t + γV(s_{t+1}) - V(s_t)
delta = self.rewards[step] + gamma * next_values * self.masks[step] - self.values[step]
# GAE: A_t = δ_t + γλA_{t+1}
advantage = delta + gamma * lam * self.masks[step] * advantage
self.returns[step] = advantage + self.values[step] # Return = Advantage + Value
# 归一化 advantages,有助于训练稳定性
self.advantages = (self.advantages - self.advantages.mean()) / (self.advantages.std() + 1e-8)GAE 解读:
lam=0.95接近 1,方差小但偏差大(偏向蒙特卡洛)gamma=0.96折扣因子,平衡近期和远期奖励最后进行归一化,使 advantages 均值为 0、方差为 1
4.10.1 观测与动作空间
状态版 PPO (shadow_hand_grasp.py)
| 项目 | 维度 | 说明 |
|---|---|---|
观测空间 num_obs | 254 | 硬编码于 ppo/module.py |
动作空间 num_actions | 21 + 6 = 27 | 21 个手指关节 + 6 个位置/姿态控制 |
观测构成(来自 shadow_hand_grasp.py):
手部状态:约 190 维(关节位置、速度、 fingertip 位置等)
物体状态:12 维
视觉特征:64 维(预提取的 point cloud 特征)
视觉版 PPO
视觉输入通过 PointNet/TransPointNet 编码为 128 维特征,拼接到手部状态后输入策略网络。
python
# ppo/module.py
self.num_obs = 191 + 29 # robot_state
if self.use_pc:
self.num_obs += 128 # 加上点云特征4.10.2 训练流程
plain text
for iteration in range(max_iterations):
1. Rollout: 每个环境收集 nsteps=8 步数据
2. 计算 GAE returns 和 advantages
3. Update: noptepochs=5, nminibatches=4
4. 每 log_interval 保存模型4.11 常见问题
Q1: 如何选择合适的学习率?
A:
使用自适应学习率调度 (
schedule: adaptive) 时,设置desired_kl在 0.01-0.02 之间固定学习率 (
schedule: fixed) 时,推荐从 3e-5 开始如果训练不稳定,降低学习率;如果收敛太慢,适当提高
Q2: 环境数量如何设置?
A:
状态输入训练:
numEnvs: 1000或更高视觉输入训练:
numEnvs: 20(受显存限制)根据 GPU 显存调整,视觉训练需要更多显存
Q3: 训练多久可以看到效果?
A:
状态输入:通常在 1000-2000 迭代后可以看到明显的策略改进
视觉输入:需要更长时间,通常 5000+ 迭代
建议观察平均奖励曲线和成功率来判断
Q4: 如何调试训练过程?
A:
启用
print_log: True查看详细日志使用 TensorBoard 监控训练指标
降低
numEnvs进行快速验证检查奖励函数设计是否合理
Q5: 视觉训练显存不足怎么办?
A:
减少
numEnvs(如从 20 减到 5)减少点云采样数量
numDownsample
使用
--freeze_backbone冻结骨干网络使用更小的 batch size
Q6: 如何提高抓取成功率?
A:
增加训练迭代次数
max_iterations调整奖励函数参数,特别是
reachGoalBonus和successTolerance
启用域随机化
--randomize增加环境数量以提高样本多样性
- 调整网络架构,增加隐藏层大小
4.12 迁移到 LinkerHand 的关键注意点
4.12.1 必改项:观测维度硬编码
问题定位:dexgrasp/algorithms/rl/ppo/module.py 中 num_obs = 254 是硬编码,且在三个方法中重复出现。
修改方案:
python
# 原代码(硬编码)
self.num_obs = 254
# 建议改为配置化
self.num_obs = model_cfg.get('num_obs', 254)关键代码位置(三处需同步修改):
python
# module.py 第 96 行、第 147 行附近、第 200 行附近
numObservations = 254 # 三处重复,需统一
# 视觉输入的切片位置也依赖此值
pc = observations[:, numObservations:numObservations+6144].reshape(-1, 1024, 6)建议重构:提取公共方法避免重复
python
def _process_observation(self, observations):
"""统一处理观测,避免三处重复代码"""
if self.use_pc:
pc = observations[:, self.num_obs:self.num_obs+6144].reshape(-1, 1024, 6)
mask = observations[:, self.num_obs+6144:].reshape(-1, 1024, 2)
state = torch.cat([observations[:, :149], observations[:, 165:190]], dim=1)
pc_feature = self.backbone({"pc": pc, "state": state, "mask": mask})[0]
return torch.cat([state, pc_feature.reshape(-1, 128)], dim=1)
return observations[:, :self.num_obs]4.12.2 必改项:机器人模型加载
修改位置:dexgrasp/tasks/shadow_hand_grasp.py 的 _create_envs 方法
python
# 原配置(ShadowHand MJCF)
asset_root = "../../assets"
shadow_hand_asset_file = "mjcf/open_ai_assets/hand/shadow_hand.xml"
# 改为 LinkerHand MJCF
shadow_hand_asset_file = "**.xml"加载后确认参数:
python
# 打印确认实际 DOF 数量
print("DOF count:", self.num_shadow_hand_dofs) # L20 应输出 20
print("Bodies count:", self.num_shadow_hand_bodies)4.12.3 必改项:Fingertip 刚体名称映射
修改位置:shadow_hand_grasp.py 的 __init__ 或 _create_envs
python
# ShadowHand 配置(原)
self.fingertips = ["j1_3", "j2_4", "j3_3", "j4_4", "j5_4"]
body_names = {
'palm': 'base_link',
'thumb': 'j1_3', 'index': 'j2_4', 'middle': 'j3_4',
'ring': 'j4_4', 'little': 'j5_4'
}
# LinkerHand 配置(示例,需根据实际 URDF 确认)
self.fingertips = ["j1_3", "j2_4", "j3_3", "j4_4", "j5_4"] # 确认 URDF 中的 link name
body_names = {
'palm': 'base_link',
'thumb': 'j1_3', 'index': 'j2_4', 'middle': 'j3_3',
'ring': 'j4_4', 'little': 'j5_4'
}验证方法:
python
# 在 _create_envs 中打印所有刚体名称
for i in range(self.num_shadow_hand_bodies):
name = self.gym.get_asset_rigid_body_name(shadow_hand_asset, i)
print(f"Body {i}: {name}")4.12.4 必改项:预抓取数据集格式
修改位置:shadow_hand_grasp.py 数据集加载部分
python
# ShadowHand: 21 关节 + 3 旋转 + 3 位置 = 27
target_qpos = torch.tensor(list(qpos.values())[:21], ...)
target_hand_rot_xyz = torch.tensor(list(qpos.values())[21:24], ...)
target_hand_pos = torch.tensor(list(qpos.values())[24:27], ...)
# LinkerHand L20: 20 关节 + 3 旋转 + 3 位置 = 26
target_qpos = torch.tensor(list(qpos.values())[:20], ...) # 改为 20
target_hand_rot_xyz = torch.tensor(list(qpos.values())[20:23], ...) # 20-23
target_hand_pos = torch.tensor(list(qpos.values())[23:26], ...) # 23-26方案选择:
重新生成:用 L20 手重新生成抓取提案数据(推荐)
映射转换:建立 ShadowHand → L20 关节映射表复用现有数据
python
# 关节映射示例(ShadowHand 24 -> L20 20)
shadow_to_l20_mapping = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19]
target_qpos = torch.tensor([list(qpos.values())[i] for i in shadow_to_l20_mapping])五、学生网络DAgger蒸馏参数简要解读
5.1 DAgger 算法概述
DAgger (Dataset Aggregation) 是一种模仿学习算法,学生网络通过模仿训练好的教师网络(专家)的动作来学习策略。与 PPO 不同,DAgger 不需要与环境交互计算优势函数,而是直接使用教师网络的输出作为监督信号。
代码位置:dexgrasp/algorithms/rl/dagger/
5.2 DAgger 核心参数解读
5.2.1 网络结构参数 (dexgrasp/cfg/dagger/config.yaml)
yaml
policy:
backbone_type: pn # 点云骨干网络类型: pn (PointNet) 或 transpn
freeze_backbone: False # 是否冻结点云骨干网络
pi_hid_sizes: [1024, 1024, 512, 512] # Actor (学生) 隐藏层
vf_hid_sizes: [1024, 1024, 512, 512] # Critic (专家) 隐藏层
activation: elu # 激活函数| 参数 | 值 | 含义 |
|---|---|---|
backbone_type | pn / transpn | 点云编码器类型,影响视觉输入处理能力 |
freeze_backbone | False | 学生网络训练时是否冻结点云骨干,通常设为 False 允许端到端训练 |
pi_hid_sizes | [1024, 1024, 512, 512] | 学生网络策略网络结构,与教师网络相同或更小 |
vf_hid_sizes | [1024, 1024, 512, 512] | 专家网络的值函数网络(仅用于加载教师模型) |
注意:DAgger 学生网络不需要值函数网络(Critic),只需要 Actor(策略网络)。vf_hid_sizes 仅用于兼容教师模型的加载。
Actor 类(学生网络)代码详解
python
# dexgrasp/algorithms/rl/dagger/module.py
class Actor(nn.Module): # 学生网络(仅 Actor,无 Critic)
def __init__(self, obs_shape, states_shape, actions_shape, initial_std, model_cfg,
asymmetric=False, use_pc=False):
super(Actor, self).__init__()
self.asymmetric = asymmetric
self.use_pc = use_pc
self.backbone_type = model_cfg['backbone_type'] # 'pn' 或 'transpn'
self.freeze_backbone = model_cfg["freeze_backbone"] # False
if model_cfg is None:
actor_hidden_dim = [256, 256, 256]
activation = get_activation("selu")
else:
actor_hidden_dim = model_cfg['pi_hid_sizes'] # [1024, 1024, 512, 512]
activation = get_activation(model_cfg['activation'])
# 关键:DAgger 观测维度是 300(与 PPO 的 254 不同!)
# 观测结构:0~191(robot state), 191-207(object state), 207~236(goal), 236~300(obj visual feat)
self.num_obs = 300
if self.use_pc:
# 视觉版:robot_state + goal_state + pointcloud feature
self.num_obs = 191 + 29 # = 220
if self.backbone_type == "pn":
self.backbone = PointNetBackbone(pc_dim=8, feature_dim=128)
elif self.backbone_type == "transpn":
self.backbone = TransPointNetBackbone(pc_dim=6, feature_dim=128)
self.num_obs += 128 # 最终:220 + 128 = 348
# 构建 Actor 网络(MLP)
actor_layers = []
actor_layers.append(nn.Linear(self.num_obs, actor_hidden_dim[0])) # 300 -> 1024
actor_layers.append(activation)
for l in range(len(actor_hidden_dim)):
if l == len(actor_hidden_dim) - 1:
actor_layers.append(nn.Linear(actor_hidden_dim[l], *actions_shape)) # 512 -> 27
else:
actor_layers.append(nn.Linear(actor_hidden_dim[l], actor_hidden_dim[l + 1]))
actor_layers.append(activation)
self.actor = nn.Sequential(*actor_layers)
print("student") # 打印标识
print(self.actor)
# 动作噪声参数(保留但训练时不使用)
self.log_std = nn.Parameter(np.log(initial_std) * torch.ones(*actions_shape))
# 权重初始化
actor_weights = [np.sqrt(2)] * len(actor_hidden_dim)
actor_weights.append(0.01)
self.init_weights(self.actor, actor_weights)
def act(self, observations):
"""训练时使用:返回动作(带梯度)"""
if self.use_pc and not self.freeze_backbone:
if self.backbone_type == "transpn":
# DAgger 点云切片位置:从 300 开始(与 PPO 的 254 不同!)
pc = observations[:, 300:300+6144].reshape(-1, 1024, 6)
mask = observations[:, 300+6144:].reshape(-1, 1024, 2)
data = {
"pc": pc,
"state": torch.cat([observations[:, :191], observations[:, 207:236]], dim=1),
"mask": mask
}
pc_feature = self.backbone(data)[0].reshape(-1, 128)
else:
pc = observations[:, 300:].reshape(-1, 1024, 8)
pc_feature = self.backbone(pc)[0].reshape(-1, 128)
# 拼接:robot_state + goal_state + pc_feature
observations = torch.cat([observations[:, :191], observations[:, 207:236], pc_feature], dim=1)
actions = self.actor(observations)
else:
actions = self.actor(observations[:, :300]) # 只取前 300 维
return actions # 返回动作(确定性,无采样)
def act_inference(self, observations):
"""推理时使用:确定性策略"""
# 与 act() 类似,但返回 detach() 后的动作
if self.use_pc and not self.freeze_backbone:
# ... 同样的处理逻辑
actions = self.actor(observations)
else:
actions = self.actor(observations[:, :300])
return actions.detach()关键代码解读:
self.num_obs = 300是 DAgger 与 PPO 的关键区别(PPO 是 254)点云切片位置
observations[:, 300:...]与 PPO 的observations[:, 254:...]不同act()方法返回确定性动作(无分布采样),直接用于 MSE Loss 计算没有
evaluate()方法(不需要计算 log_prob 和 value)log_std参数保留但不使用(为了与教师网络结构兼容)
5.2.2 DAgger 训练超参数
yaml
learn:
cliprange: 0.2 # 未使用(PPO 参数残留)
ent_coef: 0 # 未使用
buffer_size: 2000 # 经验回放缓冲区大小
nsteps: 1 # 每次迭代每环境收集的步数
noptepochs: 5 # 每个 epoch 的训练轮数
nminibatches: 4 # Mini-batch 数量
max_grad_norm: 1 # 梯度裁剪(代码中未实际使用)
optim_stepsize: 3.e-4 # Adam 学习率
schedule: adaptive # 学习率调度策略
desired_kl: 0.016 # 自适应 KL 阈值(未使用)
gamma: 0.96 # 折扣因子(仅用于日志统计)
lam: 0.95 # GAE λ(未使用)
init_noise_std: 0.8 # 动作噪声初始标准差
max_iterations: 50000 # 最大训练迭代数| 参数 | 解读 |
|---|---|
buffer_size=2000 | 关键参数:DAgger 使用固定大小的回放缓冲区,存储 (obs, action_expert, reward, done) |
nsteps=1 | 每次迭代每个环境只走 1 步就收集数据,数据实时性高 |
optim_stepsize=3e-4 | 学习率比 PPO 高 10 倍(3e-4 vs 3e-5),模仿学习任务更简单,可以更快收敛 |
noptepochs=5 | 每个 batch 数据复用 5 次进行训练 |
nminibatches=4 | 将 buffer 数据分成 4 个 mini-batch 训练 |
schedule=adaptive | 配置了但未实际使用(DAgger 没有 KL 计算) |
代码对应位置:dexgrasp/algorithms/rl/dagger/dagger.py 第 30-70 行。
5.2.3 观测与动作空间
DAgger 观测维度
python
# dagger/module.py - Actor 类
self.num_obs = 300 # 非视觉版观测维度
if self.use_pc:
self.num_obs = 191 + 29 # 视觉版:robot_state + goal_state
self.num_obs += 128 # 加上点云特征| 版本 | 观测维度 | 说明 |
|---|---|---|
| 状态版 | 300 | 纯状态输入(比 PPO 的 254 更大,可能包含更多历史信息) |
| 视觉版 | 348 (191+29+128) | 状态 + PointNet 编码后的点云特征 |
注意:DAgger 和 PPO 的观测维度不同,这是因为:
PPO:
num_obs = 254(硬编码)DAgger:
num_obs = 300(硬编码)
两者不兼容,不能直接混用观测数据。
视觉输入处理
python
# dagger/module.py
if self.backbone_type == "pn":
self.backbone = PointNetBackbone(pc_dim=8, feature_dim=128)
elif self.backbone_type == "transpn":
self.backbone = TransPointNetBackbone(pc_dim=6, feature_dim=128)pn(PointNet): 点云维度 8 (xyz + normal + mask?)transpn(Transformer PointNet): 点云维度 6 (xyz + normal),支持实例分割 mask
5.2.4 DAgger 训练流程
plain text
1. 加载预训练的 PPO 教师模型 (expert_chkpt_path)
2. for iteration in range(max_iterations):
a. Rollout: 学生网络执行动作,但存储教师网络的输出作为标签
b. 收集数据到回放缓冲区 (buffer_size=2000)
c. 从缓冲区采样 mini-batch 进行训练
d. 计算 MSE Loss: L = || student(obs) - expert(obs) ||^2
e. 梯度下降更新学生网络参数关键代码(dagger/dagger.py):
python
# Rollout 阶段
actions = self.actor.act_inference(current_obs) # 学生执行
actions_expert = self.actor_expert.act_inference(current_obs) # 教师提供标签
self.storage.add_transitions(current_obs, actions_expert, rews, dones)
# Update 阶段
actions_batch = self.actor.act(obs_batch) # 学生预测
actions_expert_batch = ... # 教师标签
loss = F.mse_loss(actions_batch, actions_expert_batch) # MSE 损失DAgger 完整训练流程代码
python
# dexgrasp/algorithms/rl/dagger/dagger.py
class DAGGER:
def __init__(self, vec_env, actor_class, actor_critic_class, ...):
# ... 初始化代码
# 学生网络:只有 Actor
self.actor = actor_class(self.observation_space.shape, self.state_space.shape,
self.action_space.shape, init_noise_std, model_cfg,
asymmetric=asymmetric, use_pc=is_vision)
# 专家网络:使用完整的 ActorCritic(从 PPO 加载)
self.actor_expert = actor_critic_class(self.expert_observation_space.shape, ...)
self.actor_expert.to(self.device)
# DAgger 缓冲区(固定大小 2000)
self.storage = RolloutStorage(self.vec_env.num_envs, self.buffer_size,
self.observation_space.shape, ...)
# 优化器:只优化学生网络的 Actor 参数
self.optimizer = optim.Adam(self.actor.parameters(), lr=learning_rate)
def run(self, num_learning_iterations, log_interval=1):
current_obs = self.vec_env.reset()
# 加载预训练的专家模型
self.actor_expert.load_state_dict(
torch.load(self.expert_chkpt_path, map_location=self.device)
)
self.actor_expert.eval() # 设为评估模式,关闭 dropout/batchnorm
for it in range(self.current_learning_iteration, num_learning_iterations):
start = time.time()
# ========== Rollout 阶段 ==========
for _ in range(self.num_transitions_per_env): # nsteps = 1
if self.apply_reset:
current_obs = self.vec_env.reset()
id = (id + 1) % self.vec_env.task.max_episode_length
# 学生网络执行动作(与环境交互)
actions = self.actor.act_inference(current_obs)
# 教师网络提供标签(不用于执行,只用于训练)
actions_expert = self.actor_expert.act_inference(current_obs)
# 环境步进
next_obs, rews, dones, infos = self.vec_env.step(actions, id)
# 存储 transition:(obs, expert_action, reward, done)
# 注意:存储的是专家动作,不是学生动作!
self.storage.add_transitions(current_obs, actions_expert, rews, dones)
current_obs.copy_(next_obs)
stop = time.time()
collection_time = stop - start
# ========== Learning 阶段 ==========
start = stop
mean_policy_loss = self.update() # 执行参数更新
stop = time.time()
learn_time = stop - start
# 日志与保存
self.log(locals())
if it % log_interval == 0:
self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))DAgger Update 方法代码
python
def update(self):
mean_policy_loss = 0
# 生成 mini-batch
batch = self.storage.mini_batch_generator(self.num_mini_batches)
for epoch in range(self.num_learning_epochs): # noptepochs = 5
for indices in batch:
# 采样数据
obs_batch = self.storage.observations.view(-1, *self.storage.observations.size()[2:])[indices]
actions_expert_batch = self.storage.actions.view(-1, self.storage.actions.size(-1))[indices]
# 学生网络预测动作(带梯度)
actions_batch = self.actor.act(obs_batch)
# ===== 核心:MSE 损失 =====
# 监督学习:让学生的输出尽可能接近专家的输出
loss = F.mse_loss(actions_batch, actions_expert_batch)
# 反向传播
self.optimizer.zero_grad()
loss.backward()
# 注意:DAgger 没有使用梯度裁剪(注释掉了)
# nn.utils.clip_grad_norm_(self.actor.parameters(), self.max_grad_norm)
self.optimizer.step()
mean_policy_loss += loss.item()
num_updates = self.num_learning_epochs * self.num_mini_batches
mean_policy_loss /= num_updates
return mean_policy_loss与 PPO 的关键区别:
| 特性 | PPO Update | DAgger Update |
|---|---|---|
| 损失函数 | Surrogate Loss + Value Loss | MSE Loss |
| 数据来源 | 自己收集的 rollout 数据 | 专家提供的标签 |
| 梯度裁剪 | 使用 (max_grad_norm=1) | 未使用 |
| 学习率 | 3e-5 | 3e-4(高 10 倍) |
| 值函数 | 需要训练 | 不需要 |
5.3 DAgger 与 PPO 的关键区别
| 特性 | PPO (教师) | DAgger (学生) |
|---|---|---|
| 学习方式 | 强化学习 (RL) | 模仿学习 (IL) |
| 损失函数 | Surrogate Loss + Value Loss | MSE Loss |
| 需要奖励 | 是 | 仅用于统计 |
| 需要值函数 | 是 (Critic) | 否 |
| 探索机制 | 动作噪声 (log_std) | 无(确定性策略) |
| 学习率 | 3e-5 (低) | 3e-4 (高 10 倍) |
| 缓冲区 | RolloutStorage (短期) | RolloutStorage (固定大小 2000) |
| 数据复用 | nsteps=8, noptepochs=5 | nsteps=1, noptepochs=5 |
| 观测维度 | 254 | 300 |
5.4 DAggerValue 扩展(带值函数的学生网络)
代码位置:dexgrasp/algorithms/rl/dagger_value/
DAggerValue 是 DAgger 的扩展版本,学生网络同时学习策略和值函数,支持:
纯模仿学习 (
apply_value_net=False): 等同于标准 DAgger混合训练 (
apply_value_net=True): DAgger + PPO 值函数训练
5.4.1 DAggerValue 特有参数
yaml
# dagger_value/config.yaml
value_loss:
apply: True # 是否启用值函数训练
use_clipped_value_loss: True # 是否使用裁剪值损失
value_loss_coef: 1.0 # 值损失系数
gamma: 0.96 # 折扣因子
lam: 0.95 # GAE lambda
clip_range: 0.2 # 值函数裁剪范围
expert: # 多专家系统配置
- name: '0'
path: 'example_model/model.pt'
object_code_dict: {...}| 参数 | 解读 |
|---|---|
apply=True | 学生网络同时训练策略(MSE)和值函数(PPO 式) |
value_loss_coef=1.0 | 值损失与策略损失的权重平衡 |
multi_expert | 支持多个专家模型,根据物体类型路由到不同专家 |
5.4.2 多专家系统
python
# dagger_value/dagger.py
class DAGGERVALUE:
def __init__(self, ...):
# ... 其他初始化
# 从配置加载多专家系统
self.expert_cfg_list = cfg['learn']['expert']
self.expert_list = []
# 初始化并加载所有专家模型
for expert_cfg in self.expert_cfg_list:
expert = actor_critic_class_expert(
self.expert_observation_space.shape,
self.state_space.shape,
self.action_space.shape,
init_noise_std, model_cfg,
asymmetric=asymmetric, use_pc=self.is_vision_expert
)
expert.to(self.device)
expert.load_state_dict(torch.load(expert_cfg['path'], map_location=self.device))
self.expert_list.append(expert)
# 建立物体 ID 到专家 ID 的映射
self.task = self.vec_env.task
id2expert_id = []
for obj_id, obj_code in enumerate(self.task.object_code_list):
result_id = -1
for expert_id, expert_cfg in enumerate(self.expert_cfg_list):
if obj_code in expert_cfg['object_code_dict']:
result_id = expert_id
break
if result_id == -1:
result_id = 0
print(f'{obj_code} not covered by all experts') # 警告:有物体未被覆盖
id2expert_id.append(result_id)
self.id2expert_id = torch.tensor(id2expert_id, dtype=torch.int64, device=self.device)
# 为每个专家计算其负责的环境索引
expert_id_buf = self.id2expert_id[self.task.object_id_buf]
for expert_id, expert_cfg in enumerate(self.expert_cfg_list):
expert_indices = torch.where(expert_id_buf == expert_id)[0]
expert_cfg['indices'] = expert_indices
print(f"Expert {expert_cfg['name']} covers indices {expert_indices}")
def expert_inference(self, current_obs):
"""
多专家推理:根据物体类型路由到对应的专家
返回合并后的动作张量
"""
action = torch.zeros((current_obs.shape[0], self.action_space.shape[0]), device=self.device)
# 遍历所有专家,分别处理其负责的样本
for expert, expert_cfg in zip(self.expert_list, self.expert_cfg_list):
indices = expert_cfg['indices'] # 该专家负责的环境索引
if len(indices) > 0:
# 只对该专家负责的样本进行推理
action[indices] = expert.act_inference(current_obs[indices])
return action
def run(self, num_learning_iterations, log_interval=1):
# ... 训练循环
for it in range(self.current_learning_iteration, num_learning_iterations):
for _ in range(self.num_transitions_per_env):
# ...
# 随机加载时,可能需要重新分配专家(物体变化了)
if id == 0:
self.task = self.vec_env.task
expert_id_buf = self.id2expert_id[self.task.object_id_buf]
for expert_id, expert_cfg in enumerate(self.expert_cfg_list):
expert_indices = torch.where(expert_id_buf == expert_id)[0]
expert_cfg['indices'] = expert_indices
# 学生执行动作
if self.apply_value_net:
actions, actions_log_prob, values, mu, sigma = self.actor.act(current_obs, current_states)
else:
actions = self.actor.act_inference(current_obs)
# 多专家提供标签
actions_expert = self.expert_inference(current_obs)
# 存储数据并更新观测
self.storage.add_transitions(current_obs, actions_expert, rews, dones)
# ...多专家系统配置示例(cfg/dagger_value/config.yaml):
yaml
learn:
expert: [
{
name: 'expert_bottles', # 专家名称
path: 'models/bottle_expert.pt', # 模型路径
object_code_dict: { # 该专家负责的物体
'core/bottle-1a7ba1f4c892e2da30711cdbdbc73924': [0.06, 0.08],
'core/bottle-e824b049f16b29f19ab27ff78a8ea481': [0.08, 0.10],
}
},
{
name: 'expert_mugs',
path: 'models/mug_expert.pt',
object_code_dict: {
'core/mug-79e673336e836d1333becb3a9550cbb1': [0.06],
'core/mug-962883677a586bd84a60c1a189046dd1': [0.08, 0.10],
}
},
{
name: 'expert_general', # 通用专家(覆盖其他物体)
path: 'models/general_expert.pt',
object_code_dict: {
# 包含所有其他物体...
}
}
]多专家系统的优势:
专业化:每个专家针对特定物体类别优化
可扩展性:可以添加新专家而无需重新训练现有专家
- 容错性:如果一个物体未被任何专家覆盖,会使用默认专家(索引 0)
5.5 蒸馏训练的关键注意点
5.5.1 教师-学生观测一致性
问题:PPO 教师使用 254 维观测,DAgger 学生使用 300 维观测。
解决方案:
重新训练教师:使用 300 维观测训练新的 PPO 教师
观测对齐:修改 DAgger 的
num_obs为 254,与教师一致
- 特征蒸馏:教师输出层与学生输入层对齐
建议修改(dagger/module.py):
python
# 将 num_obs 改为与教师一致
self.num_obs = 254 # 与 PPO 教师网络兼容5.5.2 动作分布对齐
教师网络输出动作均值 actions_mean 和 log_std,但 DAgger 学生只学习均值(确定性策略)。
注意:
DAgger 学生网络仍然保留
log_std参数(继承自网络结构),但训练时不使用推理时学生输出确定性动作(
act_inference直接返回actions_mean)
5.5.3 专家模型加载路径
python
# dagger/dagger.py
self.expert_chkpt_path = expert_chkpt_path # 从配置传入
# 加载专家
self.actor_expert.load_state_dict(
torch.load(self.expert_chkpt_path, map_location=self.device)
)
self.actor_expert.eval() # 专家设为评估模式注意:
专家模型必须是 PPO 训练好的
ActorCritic完整模型加载后必须调用
eval()关闭 dropout/batchnorm 等训练行为
5.5.4 缓冲区管理
python
# dagger/storage.py
class RolloutStorage:
"""
DAgger 使用的简化版回放缓冲区
只存储观测、专家动作、奖励和 done 标志
"""
def __init__(self, num_envs, buffer_size, obs_shape, state_shape, action_shape, device, sampler):
self.num_envs = num_envs
self.buffer_size = buffer_size # 2000(固定大小)
# 分配存储空间
self.observations = torch.zeros(num_envs, buffer_size, *obs_shape, device=device)
self.actions = torch.zeros(num_envs, buffer_size, *action_shape, device=device) # 专家动作
self.rewards = torch.zeros(num_envs, buffer_size, device=device)
self.dones = torch.zeros(num_envs, buffer_size, device=device)
self.step = 0 # 当前写入位置
self.device = device
def add_transitions(self, obs, actions, rewards, dones):
"""添加 transition 到缓冲区"""
# 写入当前位置(循环覆盖)
self.observations[:, self.step] = obs.clone()
self.actions[:, self.step] = actions.clone()
self.rewards[:, self.step] = rewards.clone()
self.dones[:, self.step] = dones.clone()
self.step = (self.step + 1) % self.buffer_size # 循环覆盖旧数据
def mini_batch_generator(self, num_mini_batches):
"""生成 mini-batch 采样器"""
batch_size = self.num_envs * self.step
batch_size_per_mini_batch = batch_size // num_mini_batches
# 随机打乱索引
rand = torch.randperm(batch_size)
for i in range(num_mini_batches):
start = i * batch_size_per_mini_batch
end = (i + 1) * batch_size_per_mini_batch
yield rand[start:end]代码对比:
python
# PPO 存储(复杂)
self.storage.add_transitions(
current_obs, current_states, actions, rews, dones,
values, # 需要值函数输出
actions_log_prob, # 需要 log_prob
mu, sigma # 需要分布参数
)
# DAgger 存储(简单)
self.storage.add_transitions(
current_obs,
actions_expert, # 直接存储专家动作,无需其他信息
rews, dones
)5.5.5 学习率与收敛
| 参数 | PPO | DAgger | 说明 |
|---|---|---|---|
| 学习率 | 3e-5 | 3e-4 | DAgger 任务更简单,可用更高 lr |
| 收敛速度 | 慢(需探索) | 快(直接模仿) | DAgger 通常 1000-5000 迭代收敛 |
| 最终性能 | 可能更高 | 受限于教师 | 学生性能 ≤ 教师性能 |
5.6 配置文件速查表
5.6.1 DAgger 标准配置
yaml
# cfg/dagger/config.yaml
seed: -1
clip_observations: 5.0
clip_actions: 1.0
policy:
backbone_type: pn
freeze_backbone: False
pi_hid_sizes: [1024, 1024, 512, 512]
vf_hid_sizes: [1024, 1024, 512, 512]
activation: elu
learn:
agent_name: shadow_hand
test: False
resume: 0
save_interval: 200
print_log: True
max_iterations: 50000
cliprange: 0.2 # 未使用
ent_coef: 0 # 未使用
buffer_size: 2000 # 关键参数
nsteps: 1
noptepochs: 5
nminibatches: 4
max_grad_norm: 1
optim_stepsize: 3.e-4 # 关键参数(比 PPO 高 10 倍)
schedule: adaptive # 未实际使用
desired_kl: 0.016
gamma: 0.96
lam: 0.95
init_noise_std: 0.8
log_interval: 1
asymmetric: False5.6.2 DAggerValue 配置
yaml
# cfg/dagger_value/config.yaml
vision: True # 启用视觉输入
policy:
pi_hid_sizes: [1024, 1024, 512, 512]
vf_hid_sizes: [1024, 1024, 512, 512]
activation: elu
learn:
buffer_size: 2000
nsteps: 1
noptepochs: 5
nminibatches: 4
optim_stepsize: 3.e-4
value_loss: # 值函数训练配置
apply: True
use_clipped_value_loss: True
value_loss_coef: 1.0
gamma: 0.96
lam: 0.95
clip_range: 0.2
expert: # 多专家配置
- name: '0'
path: 'example_model/model.pt'
object_code_dict: {...}